Workshop 1 - Exploring Categorical Variables
- Extracting subsets of a data set using
[] - Drawing simple barplots using
barplotto show the distribution of a categorical variable - Using
pieto draw pie charts to represent proportions
1 R Methods and Techniques
1.1 Loading data and getting started
For these workshops, we will provide RData files which will be indicated as below:
Download data: Marriage
Files with an extension “Rda” are R DAta files, and can be loaded directly into R. First, download the file and save it somewhere easily accessible (you can always move it later). You may want to save it to the same place as your R code and set that place to be R’s working directory. Once saved, there are various options to load the data file:
- In RStudio, open the
Sessionmenu and clickLoad Workspace.... Select the data file to load and click Open. - In RStudio click the
Filetab in the bottom right panel of the screen. Use the file browser to locate the file, and simply click it to load. If you can’t find your saved file, you may need to move it to a place RStudio can find (usually this excludes external drives, cloud storage, or similar.) - Or, run the following line of code to open a file selection window to navigate to and select the file. Once found, click open and the file will load into R.
load(file.choose())- Or, if the path to the file is short (such as
C:/data/file.Rda), you can simply use theloadfunction and type the file path:
load("C:/data/file.Rda")Advanced: To make life easier in the long-term, you can set your computer to automatically open .Rda files using RStudio. This is a more advanced solution, so you’ll have to figure out the details from the appropriate link below. Once set up, you’ll be able to load .Rda files into RStudio just by double-clicking.
1.2 Manipulating data: Extracting a subset
The Marriage dataset contains the marriage records of 98 individuals in Mobile County, Alabama from the late 1990s. Looking at the first few rows of the data, we can see the data contains a lot of variables, some categorical, some numerical, some dates, and some other junk.
head(Marriage)| bookpageID | appdate | ceremonydate | delay | officialTitle | person | dob | age | race | prevcount | prevconc | hs | college | dayOfBirth | sign |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| B230p539 | 1996-10-29 | 1996-11-09 | 11 | CIRCUIT JUDGE | Groom | 2064-04-11 | 32.60274 | White | 0 | NA | 12 | 7 | 102 | Aries |
| B230p677 | 1996-11-12 | 1996-11-12 | 0 | MARRIAGE OFFICIAL | Groom | 2064-08-06 | 32.29041 | White | 1 | Divorce | 12 | 0 | 219 | Leo |
| B230p766 | 1996-11-19 | 1996-11-27 | 8 | MARRIAGE OFFICIAL | Groom | 2062-02-20 | 34.79178 | Hispanic | 1 | Divorce | 12 | 3 | 51 | Pisces |
| B230p892 | 1996-12-02 | 1996-12-07 | 5 | MINISTER | Groom | 2056-05-20 | 40.57808 | Black | 1 | Divorce | 12 | 4 | 141 | Gemini |
| B230p994 | 1996-12-09 | 1996-12-14 | 5 | MINISTER | Groom | 2066-12-14 | 30.02192 | White | 0 | NA | 12 | 0 | 348 | Saggitarius |
| B230p1209 | 1996-12-26 | 1996-12-26 | 0 | MARRIAGE OFFICIAL | Groom | 1970-02-21 | 26.86301 | White | 1 | NA | 12 | 0 | 52 | Pisces |
While we usually always start looking at all the data in a data set
at once, we very often will want to focus on a particular set of data
points (such as marriages after a particular date, or only the brides’
records) from a data frame. We can do so using the [ and
] characters.
The data set (in R these objects are called data frames)
is effectively a matrix - in the mathematical sense - so it can be
treated as a grid of data values, where each row is a data point and
each column a variable. We can use this idea to extract parts of the
data set by selecting particular rows or columns. For example, to
extract the 10th row in the data, we can type
Marriage[10,]## bookpageID appdate ceremonydate delay officialTitle person dob age race prevcount
## 10 B231p48 1997-03-12 1997-03-22 10 MINISTER Groom 2051-07-02 45.75342 White 3
## prevconc hs college dayOfBirth sign
## 10 Divorce 12 6 183 CancerThe comma here is important - anything after the comma indicates which columns we want to extract. Here we leave it blank, which returns all the columns. Alternatively, we could specify specific columns by name or number. Extending this idea, typing
y = Marriage[c(3,6,9,12),5:10]will create a new data frame consisting of columns 5 to 10 of the
3rd, 6th, 9th and 12th rows of the Marriage data frame, all
saved to a new variable called y. This can be useful when
you want to regularly work with a particular subset of data and want to
save typing.
We can also use a logical test to extract only those rows which match a particular condiation. For example, to get only the marriage records of those with more than 1 previous marriage we could type
Marriage[Marriage$prevcount>1,]Or all the marriages officiated by a judge:
Marriage[Marriage$officialTitle=="CIRCUIT JUDGE",]Note the use of == with two = signs - this
indicates a test for equality, rather than an
assignment of one variable to another.
We can apply the same techniques to extract elements of a vector,
only now we drop the , in the [] as a vector
only has a length. So, the 10th recorded value of age could
be found by typing:
Marriage$age[10]## [1] 45.753421.3 Barcharts and Piecharts
The barplot is useful for summarizing categorical data.
Continuing with the Marriage data, let’s look at who
officiated at these weddings - as indicated by the
officialTitle variable. If we look at the first few values
in the officialTitle variable, we find:
Marriage$officialTitle[1:10]## [1] CIRCUIT JUDGE MARRIAGE OFFICIAL MARRIAGE OFFICIAL MINISTER MINISTER
## [6] MARRIAGE OFFICIAL MARRIAGE OFFICIAL MARRIAGE OFFICIAL MARRIAGE OFFICIAL MINISTER
## 9 Levels: BISHOP CATHOLIC PRIEST CHIEF CLERK CIRCUIT JUDGE ELDER MARRIAGE OFFICIAL MINISTER ... REVERENDWe can see that there are a variety of different officials. Notice
also that below the data is a line labelled Levels - here R
is being helpful and listing all of the possibilities for this
particular categorical variable. To visualise the distribution we must
find the counts (or proportions) of each in the data set.
Before doing so, which do you think would be most (least) common?
Now we use the xtabs function to do the counting of the
different genders before plotting:
xtabs(~officialTitle, data=Marriage) ## this makes the table of counts for the officialTitle variable in the Marriage data set## officialTitle
## BISHOP CATHOLIC PRIEST CHIEF CLERK CIRCUIT JUDGE ELDER MARRIAGE OFFICIAL
## 2 2 2 2 2 44
## MINISTER PASTOR REVEREND
## 20 22 2The syntax is a little odd here, note the use of the ~
(tilde) sign, which you may recognise from fitting linear regressions
with lm. The variable name to the right of the
~ is the one we want summarising as counts.
Did this agree with what you expected?
We can then pass this summary table to the barplot
function for plotting. Since we’ll be working with this table for a
while, we can also save it to a variable to save repetition.
offs <- xtabs(~officialTitle, data=Marriage) ## save the table to `offs`
barplot(offs, col='skyblue')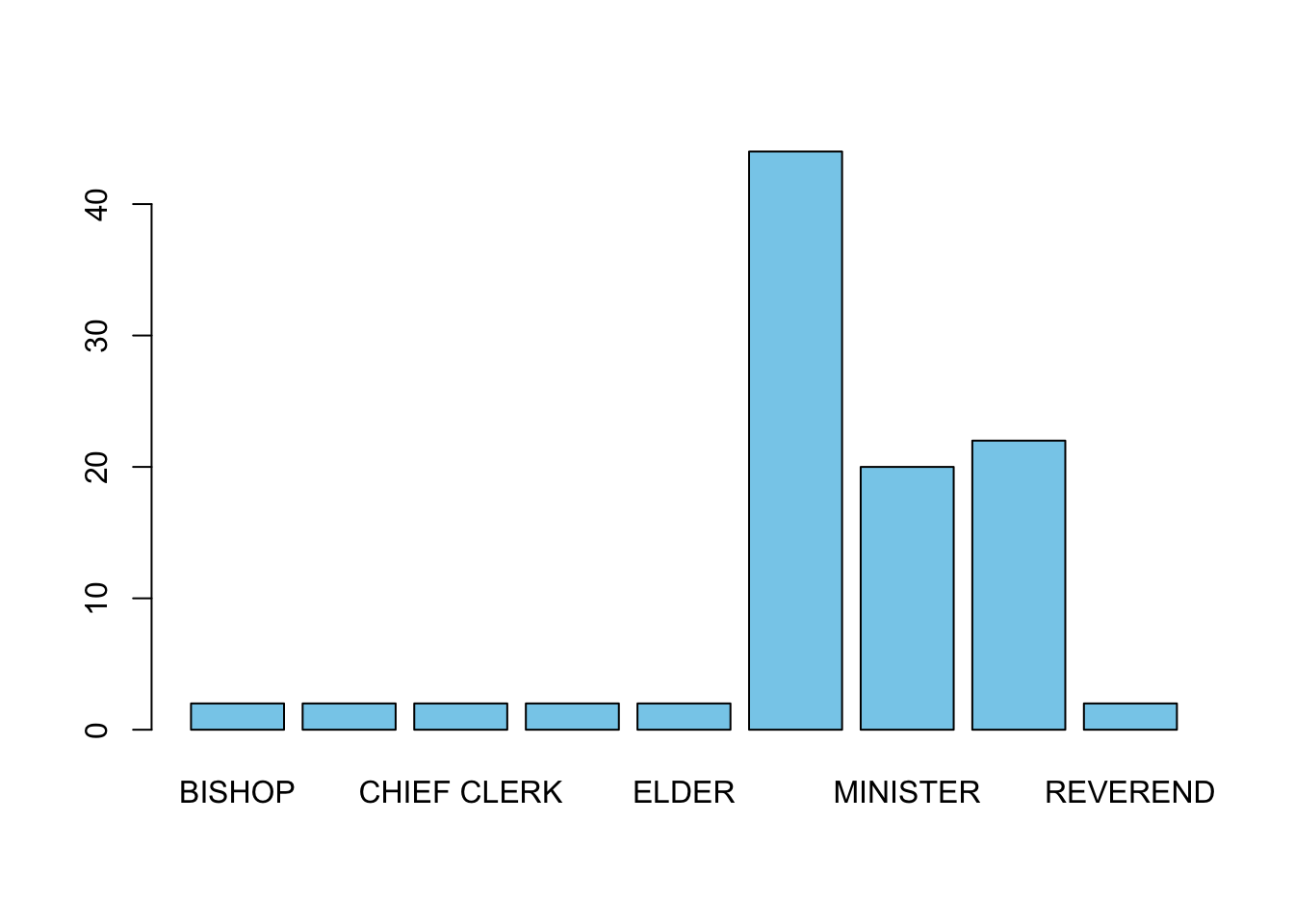
Unfortunately, not all of our category labels are displayed due to
the restricted space. We can make the labels perpendicular to the axis
with the optional argument las=2, which improves things
enough to be readable:
barplot(offs, las=2, col='skyblue')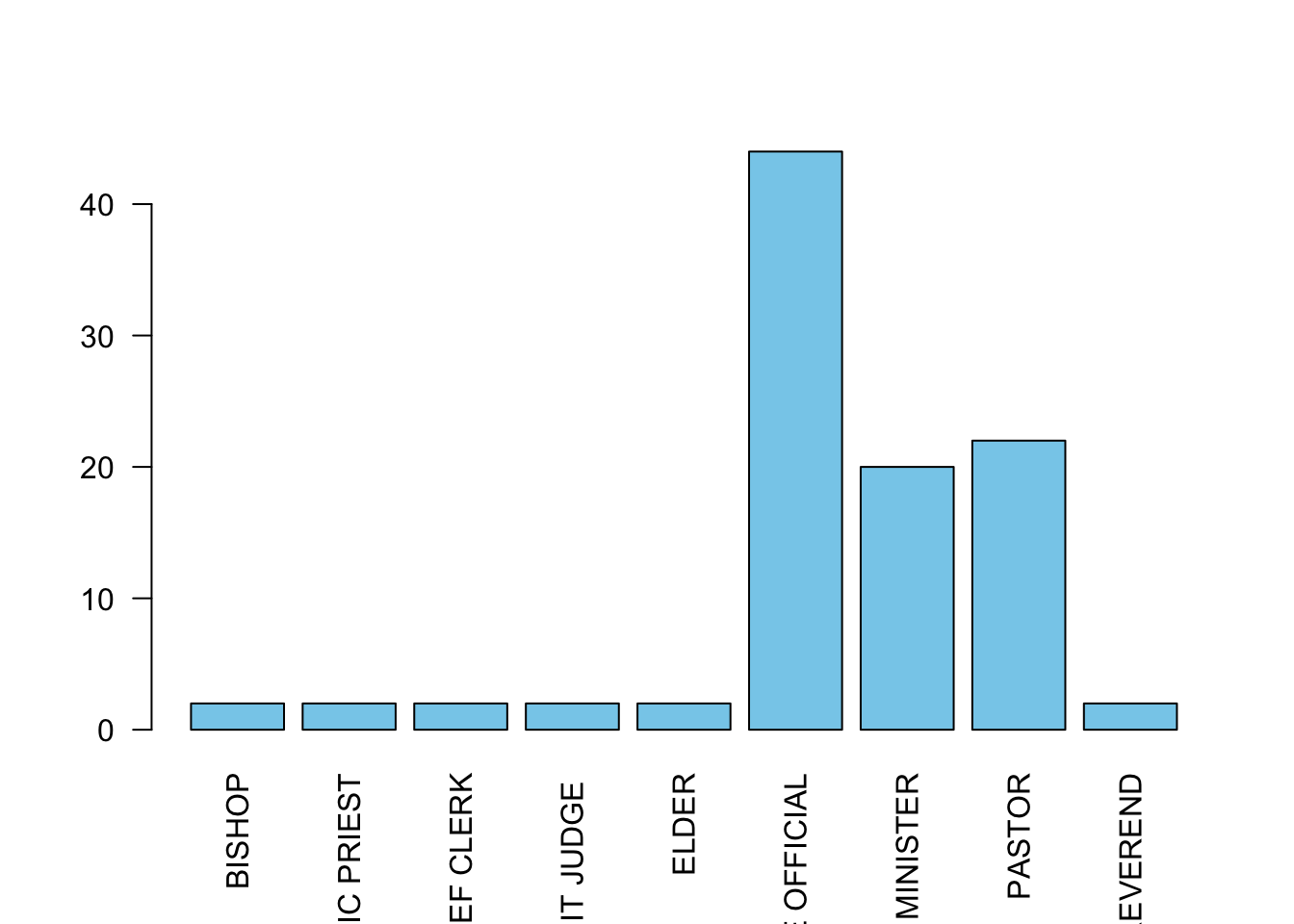
Note that some data sets may give you the counts of the categories
directly and you can skip the call to xtabs, so it is
always important to look at your data before plotting.
Like the other plotting functions we have seen, we can customise this
with axis labels and colours to fill the bars. The barplot
also supports the following additional arguments to customise the
plot:
names- use this to pass a vector of labels for each barhorizontal- set toTRUEto show a horizontal barplot. Defaults toFALSEand a vertical presentationwidth- use this to supply a vector of values to specify the widths of the barsspace- use this to supply a vector of values to specify the spacing between bars
1.3.1 Pie charts
The many issues
with pie charts notwithstanding, generating a pie chart is
relatively easy with the function pie. Note that the pie
chart emphasises showing the data as proportions of the whole,
rather than separate counts.
pie takes the same data input as the barplot, and can be
supplied with labels, and given custom colours
for the wedges. We’ll stick with the defaults for now, but feel free to
experiment.
pie(offs)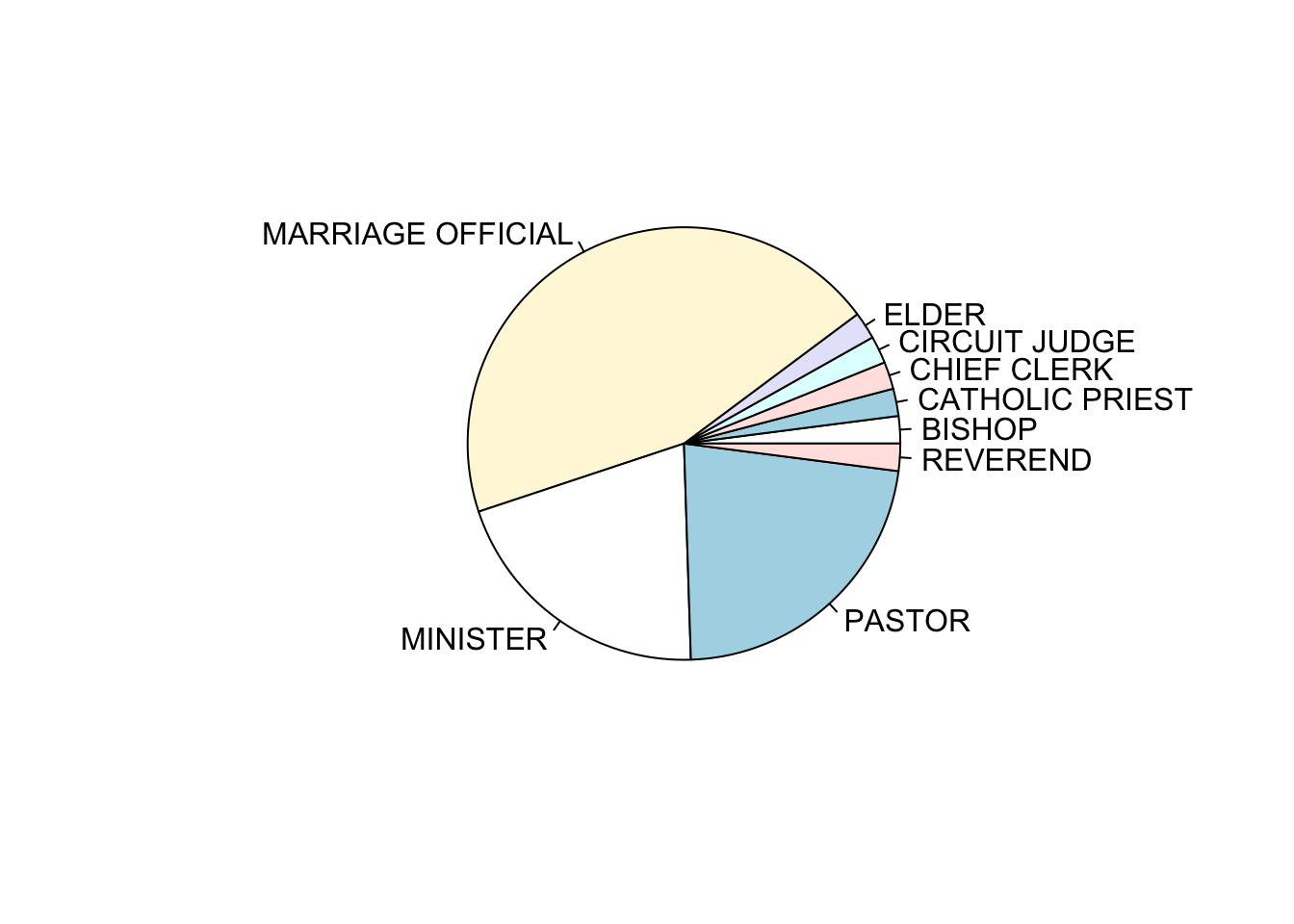
If your goal is compare each category with the the whole (e.g., what portion of weddings are officiated by a Bishop compared to all participants), and the number of categories is small, then pie charts may work for you. However, the best alternative to a piechart is the barchart, but if you really want to show proportions of a whole via area, then a treemap is a better choice (see below).
1.4 Combining Plots
R makes it easy to combine multiple plots into one overall
graph, using either the par or layout
functions.
With the par function, we specify the argument
mfrow=c(nr, nc) to split the plot window into a grid of nr
x nc plots that are filled in by row. For example, to divide the plot
window into a 2x2 grid we call par(mfrow=c(2,2)) as
below
Similarly, for 3 plots in a single column we use we
par(mfrow=c(3,1))
The plot window will remain divided like this until you reset it, and
any new plots draw will fit into your grid. To return to the usual
single-plot display, we must call par(mfrow=c(1,1)).
If we don’t want to arrange plots in a simple regular grid and have
something more complex in mind, we can use the layout
function.
2 Data Analysis
2.1 Data Set 1: Alzheimer’s
Download data: alzheimer
Some simple practice to get started.
Three groups of patients (one with Alzheimer’s, one with other forms
of dementia, and a control group with other diagnoses) were studied.
Counts are given in the alzheimer data linked above. Create a graphical
summary of barplots of each of the three variables, smoking
(cigarettes per day), disease, and gender, in
a single window.
- Are the disease groups very different in size? Which group is largest?
- Are there more men or women in the study?
- How would you describe the distribution of the smoking variable? Do you think the smoking data are likely to be reliable?
- Now plot the same data using pie charts - do you find the questions above easier to answer, harder to answer, or about the same?
2.2 Data Set 2: British Election survey data
Download data: beps
In many surveys there is a string of questions to which respondents give answers on integer scales from, say, 1 to 5. This is so commonplace that one such scale even has a name - the Likert scale.
The beps dataset includes seven questions put to 1525
voters in the British Election Panel Study for 1997-2001. One question
was on a scale from 1 to 11, one from 0 to 3, and the rest were from 1
to 5.
The leaders of the main political parties at the time were Tony Blair for Labour (the Prime Minister at the time), William Hague for the Conservatives, and Charles Kennedy for the Liberal Democrats. Each surveyed individual assessed each party leader on a scale of 1 to 5 (5=best).
- Load the
bepsdata set from the file above. Use theheadfunction to get a quick look at the first few rows of the data to see what the variables are and how they are represented. - Let’s begin with the party leader data:
- Split your plot display to show a single row of three plots.
- Draw a barplot of each of the party leader’s ratings as contained in
the three variables
Blair,HagueandKennedy. Don’t forget to call thextabsfunction to summarise the data before plotting. - Colour your barplots by the corresponding party colours (red, blue, and yellow respectively.).
- Can you see any similarities in the distributions of the assessments
of
BlairandHague? How would you interpret these patterns? - What do you find about the assessments of
Kennedy? - Repeat the plots using pie charts - which plots do you find easier to read and interpret?
In addition to assessing the party leaders, two further variables concerned Europe. The first asked the respondents to quantify their knowledge of the parties’ policies on European integration from low knowledge (0) to high knowledge (3), and the second measures the individuals attitudes to European integration from 1 to 11, where higher values are more Eurosceptic.
- First, investigate the respondents knowledge of the parties’
policies on Europe as contained in the
political.knowledgevariable. Reset your plot window to show a single plot, and plot the data - how would you describe and explain what you find? - Now investigate the
Europevariable representing individual attitudes towards Europe. Do any features stand out? - The data set also contains a column representing the voting
intentions of the individuals surveyed in the
votevariable. Plot the voting intentions - can you explain what you find? (Bear in mind the survey was taken over 1997-2001!) - Now, let’s dig a little deeper and think about how attitudes to
Europe may differ between the different party voters:
- Before doing anything - think a little about what you expect to see.
- Now, split the plot window into three, extract the data
corresponding to those individuals who intend to
voteforLabour, and plot their attitudes to Europe, using party colours as above. Add amainplot label to indicate the party. - Repeat for
ConservativeandLiberal Democratvoters. - What features do you see? Are there any surprises, or does this confirm what you expected?
2.3 Data Set 3: Occupational Mobility
Download data: occupation
The data set above were presented by Yamaguchi (1987), and looks at the categories of occupation of fathers and sons in the USA, UK and Japan. The occupations of the fathers and sons are grouped into categories:
UpNM- Upper nonmanuals - are professionals, managers, and officials;LoNM- lower nonmanuals - are proprietors, sales workers, and clerical workers;UpM- upper manuals - are skilled workers;LoM- lower manuals - are semi-skilled and unskilled nonfarm workers;Farm- farmers and farm laborers.
The data already contains the counts for the various categories, so we’ll need to work with the data slightly differently.
- Look at the first few rows of the data. You’ll see that we already
have the data summarised as counts (
Freq) of the combinations of the three categorial variables (Son,Father, andCountry). The first row of the data set corresponds to 1275 observations of(UpNM,UpNM,US). - However, if we’re only interested in one of the variables, such as
Countrythen there’s still some more summarising to be done. To do this, we can still use thextabsfunction, but we modify the syntax to reflect that theFreqcolumn already contains count information. So, to obtain the counts per country, we typextabs(Freq~Country, data=occupation). - Draw a plot of the counts by country.
- Repeat the step above for the other two variables.
- How do the distributions of occupations of the sons in the three countries compare?
- Extract the data corresponding where
CountryisUKand save to a new variable. - How do the distributions of the sons’ and fathers’ occupations in the UK compare?
- Are you surprised by the results or are they what you expected?
3 Variations on Standard Plots
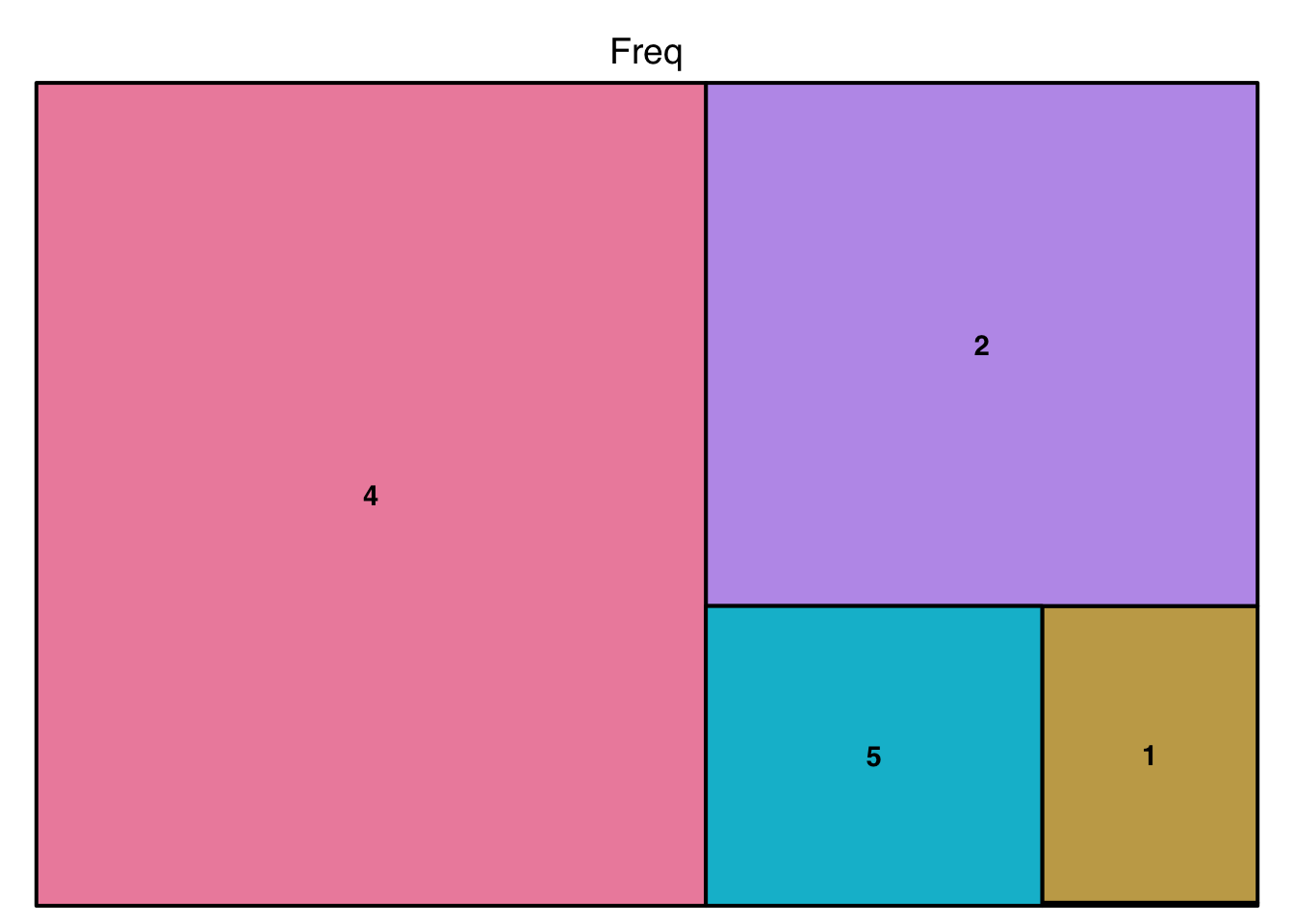
3.1 Treemap
A treemap can be used as an alternative to a pie chart for displaying relative sizes of groups as a proportion of a larger whole. Unlike the pie chart, which divides a circle into wedges, the treemap divides a rectangle into smaller rectangles.
The setup of a treemap is a bit more involved as we need to explicitly identify the data counts, and the labels, and provide them as a data frame. For example, to show the approval ratings for Tony Blair:
# you'll need to install `treemap` if you don't have it
# install.packages("treemap")
library(treemap)
# Create data
data <- data.frame(table(beps$Blair))
# treemap
treemap(data,
index="Var1", ## the name of the variable which contains the labels
vSize="Freq" ## the name of the variable which contains the counts
)
The treemap is most effective at showing data where there are multiple groups, e.g. the five approval ratings split up by Labour, Conservative and Liberal voters. Then each panel will be sub-divided into its subgroups. This requires a fair bit more work, so we’ll skip it for now.