Workshop 4 + Solutions - Dependency, Relationships and Associations
- Extracting and working with subsets of a data set using
[] - Drawing scatterplots of pairs of continuous variables
- Using transparency in your visualisations
You will need to install the following packages for today’s workshop:
scalesfor thealphafunction for transparency in plots
Custom packages are exceptionally useful in R, as they provide more specialised functionality beyond what is included in the base version of R. We will typically make use of custom packages to access specialised visualisation functions or particular data sets that are included in the package.
There are many ways to install a new package. Here are a few of the easiest:
- In RStudio, open the Tools menu and select
Install Packages.... Type the name of the package, and click install. - In the console, type
install.packages("pkgname")where you replacepkgnamewith the name of the package you want to install.
install.packages("scales")1 Manipulating data: Extracting a subset
Download data: Marriage
The Marriage dataset contains the marriage records of 98 individuals in Mobile County, Alabama from the late 1990s. Looking at the first few rows of the data, we can see the data contains a lot of variables, some categorical, some numerical, some dates, and some other junk.
head(Marriage)| bookpageID | appdate | ceremonydate | delay | officialTitle | person | dob | age | race | prevcount | prevconc | hs | college | dayOfBirth | sign |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| B230p539 | 1996-10-29 | 1996-11-09 | 11 | CIRCUIT JUDGE | Groom | 2064-04-11 | 32.60274 | White | 0 | NA | 12 | 7 | 102 | Aries |
| B230p677 | 1996-11-12 | 1996-11-12 | 0 | MARRIAGE OFFICIAL | Groom | 2064-08-06 | 32.29041 | White | 1 | Divorce | 12 | 0 | 219 | Leo |
| B230p766 | 1996-11-19 | 1996-11-27 | 8 | MARRIAGE OFFICIAL | Groom | 2062-02-20 | 34.79178 | Hispanic | 1 | Divorce | 12 | 3 | 51 | Pisces |
| B230p892 | 1996-12-02 | 1996-12-07 | 5 | MINISTER | Groom | 2056-05-20 | 40.57808 | Black | 1 | Divorce | 12 | 4 | 141 | Gemini |
| B230p994 | 1996-12-09 | 1996-12-14 | 5 | MINISTER | Groom | 2066-12-14 | 30.02192 | White | 0 | NA | 12 | 0 | 348 | Saggitarius |
| B230p1209 | 1996-12-26 | 1996-12-26 | 0 | MARRIAGE OFFICIAL | Groom | 1970-02-21 | 26.86301 | White | 1 | NA | 12 | 0 | 52 | Pisces |
While we usually always start looking at all the data in a data set
at once, we very often will want to focus on a particular set of data
points (such as marriages after a particular date, or only the brides’
records) from a data frame. We can do so using the [ and
] characters.
The data set (in R these objects are called data frames)
is effectively a matrix - in the mathematical sense - so it can be
treated as a grid of data values, where each row is a data point and
each column a variable. We can use this idea to extract parts of the
data set by selecting particular rows or columns. For example, to
extract the 10th row in the data, we can type
Marriage[10,]## bookpageID appdate ceremonydate delay officialTitle person dob age race prevcount
## 10 B231p48 1997-03-12 1997-03-22 10 MINISTER Groom 2051-07-02 45.75342 White 3
## prevconc hs college dayOfBirth sign
## 10 Divorce 12 6 183 CancerThe comma here is important - anything after the comma indicates which columns we want to extract. Here we leave it blank, which returns all the columns. Alternatively, we could specify specific columns by name or number. Extending this idea, typing
y = Marriage[c(3,6,9,12),5:10]will create a new data frame consisting of columns 5 to 10 of the
3rd, 6th, 9th and 12th rows of the Marriage data frame, all
saved to a new variable called y. This can be useful when
you want to regularly work with a particular subset of data and want to
save typing.
We can also use a logical test to extract only those rows which match a particular condiation. For example, to get only the marriage records of those with more than 1 previous marriage we could type
Marriage[Marriage$prevcount>1,]Or all the marriages officiated by a judge:
Marriage[Marriage$officialTitle=="CIRCUIT JUDGE",]Note the use of == with two = signs - this
indicates a test for equality, rather than an
assignment of one variable to another.
We can apply the same techniques to extract elements of a vector,
only now we drop the , in the [] as a vector
only has a length. So, the 10th recorded value of age could
be found by typing:
Marriage$age[10]## [1] 45.75342- Produce a histogram of the
ageof the participants - what do you see? - Now draw a pair of histograms of
age- one for those where thepersonis theGroom, and another for theBride. - Compare the distributions of
agefor those getting married for the first time, and those who have been married before. What do you find?
hist(Marriage$age) 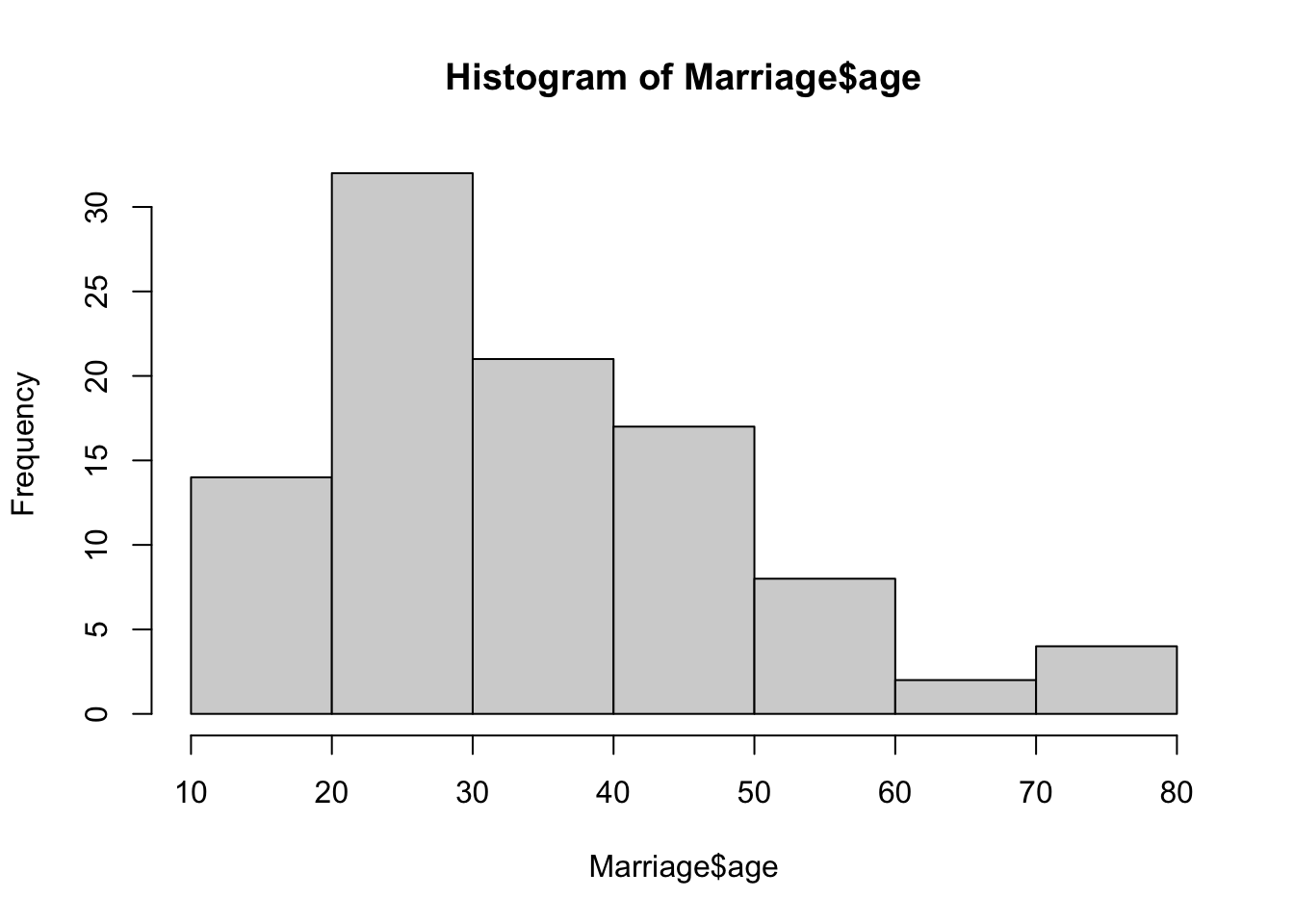
# slightly skewed to the right - to be expected as people generally marry when younger and there is a minimum age
par(mfrow=c(1,2))
hist(Marriage$age[Marriage$person=="Groom"],breaks=14) ## increase the default number of breaks
## looks to be a peak in the early 20s, around 40, and another 65+!
hist(Marriage$age[Marriage$person=="Bride"])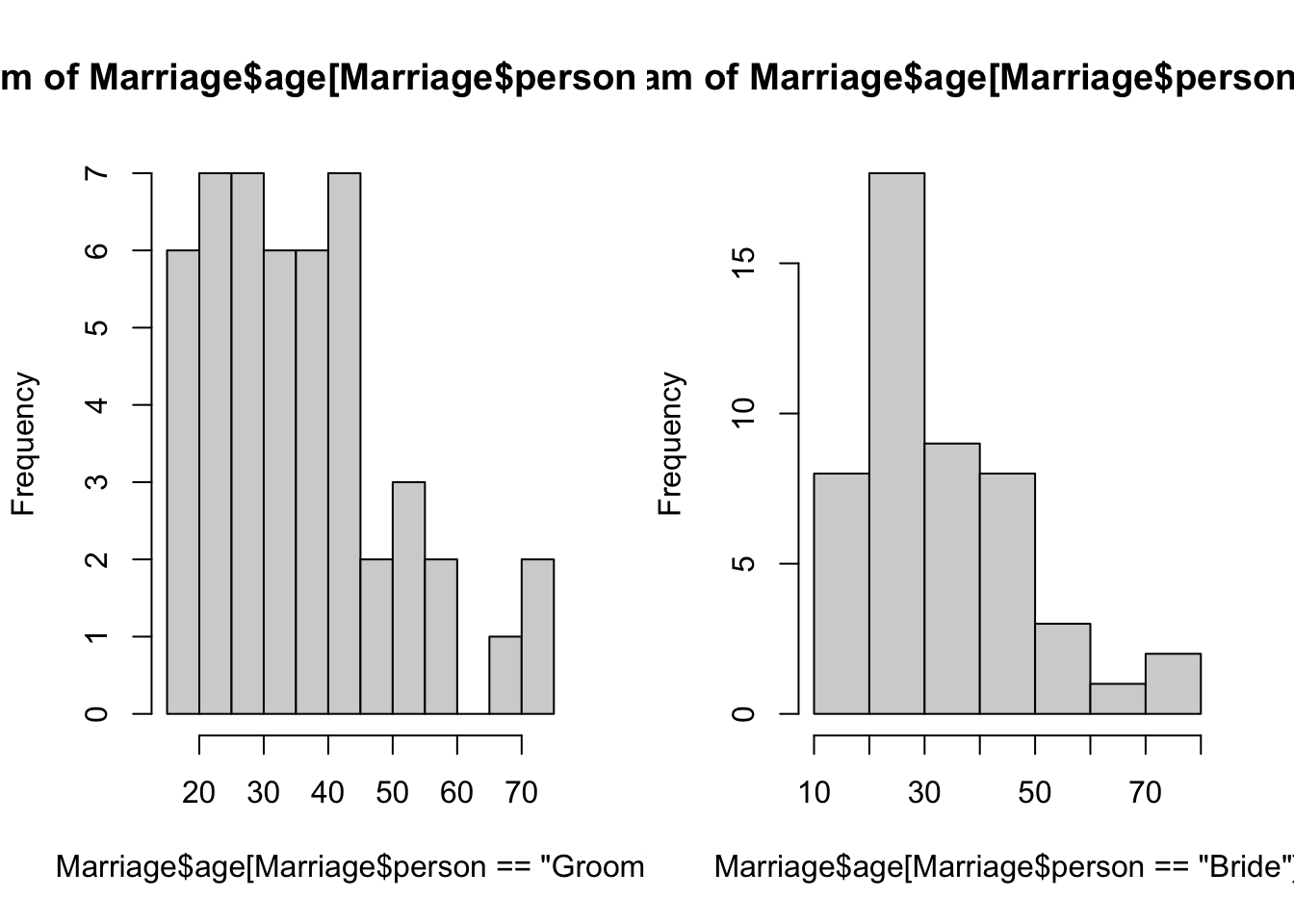
## age distribution a little flatter, but drops sharply after 45. Another small group of happy pensioners.2 Drawing Scatterplots
Scatterplots are another rather simple plot, but incredibly effective at showing structure in the data. By simply plotting points at the coordinates of two numerical variables, we can easily detect any patterns that may appear.
The plot function produces a scatterplot of its two
arguments. For illustration, let us use the mtcars data set
again, containing information on the characteristics of 23 cars. We can
plot miles per gallon against weight with the command
data(mtcars)
plot(x=mtcars$wt, y=mtcars$mpg)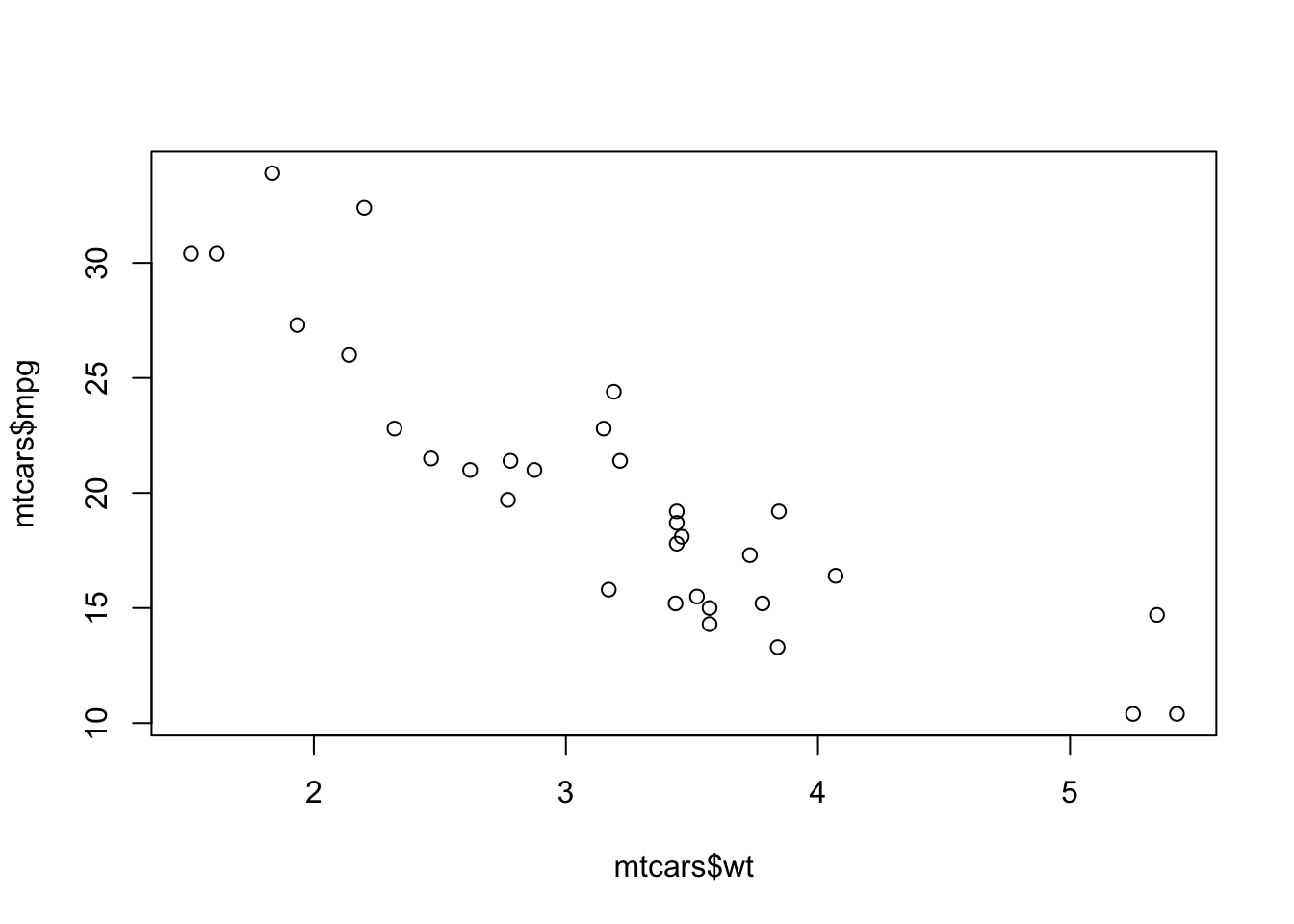
Unsurprisingly, heavier cars do fewer miles per gallon and are less efficient. The relationship here, while clear and negative, is far from exact with a lot of noise and variation.
If the argument labels x and y are not
supplied to plot, R will assume the first argument
is x and the second is y. If only one vector
of data is supplied, this will be taken as the \(y\) value and will be plotted against the
integers 1:length(y), i.e. in the sequence in which they
appear in the data.
2.1 Customising the plot type
Another useful optional argument is type, which can
substantially change how plot draws the data. The
type argument can take a number of different values to
produce different types of plot:
type="p"- draws a standard scatterplot with a point for every \((x,y)\) pairtype="l"- connects adjacent \((x,y)\) pairs with straight lines, does not draw points. Note this is a lowercase L, not a number 1.type="b"- draws both points and connecting line segmentstype="s"- connects points with ‘steps’ rather than straight lines
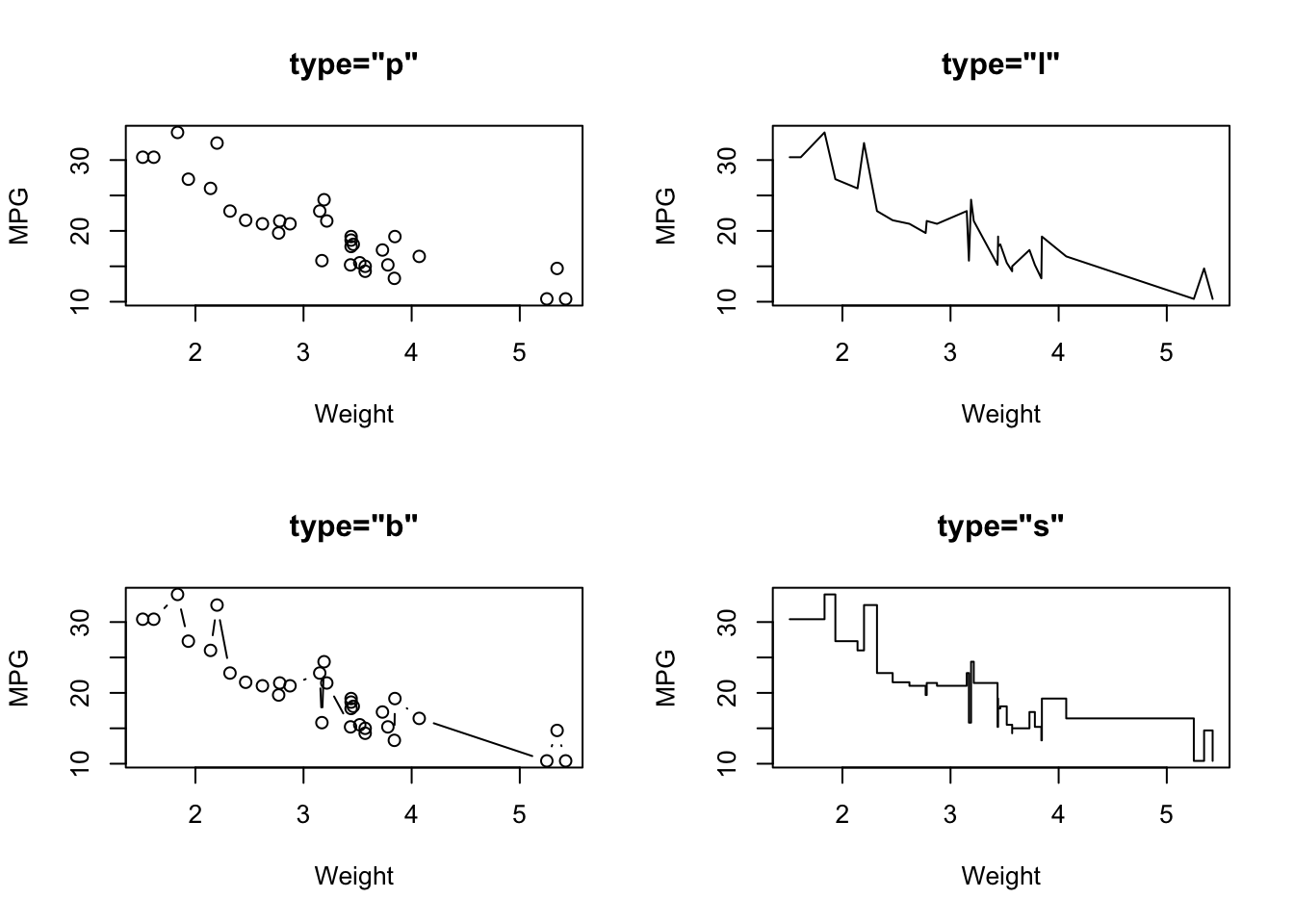
2.2 Plot symbols
The symbols used for points in scatter plots can be changed by
specifying a value for the argument pch {#pch} (which
stands for plot character). Specifying
values for pch works in the same way as col,
though pch only accepts integers between 1 and 20 to
represent different point types. The default is pch=1 which
is a hollow circle. The possible values of pch are shown in
the plot below:

- Experiment with using the
pchargument to adjust the plot points used in the scatterplot above. Which plot symbols do you find most effective?
2.3 Overplotting and transparency
To deal with issues of overplotting - where dense areas of points are drawn ontop of each other - we can use transparency to make the plot symbols. For example, here are 500 points randomly generated from a 2-D normal distribution. Notice how the middle of the plot is a solid lump of black
plot(x=rnorm(5000),y=rnorm(5000),pch=16)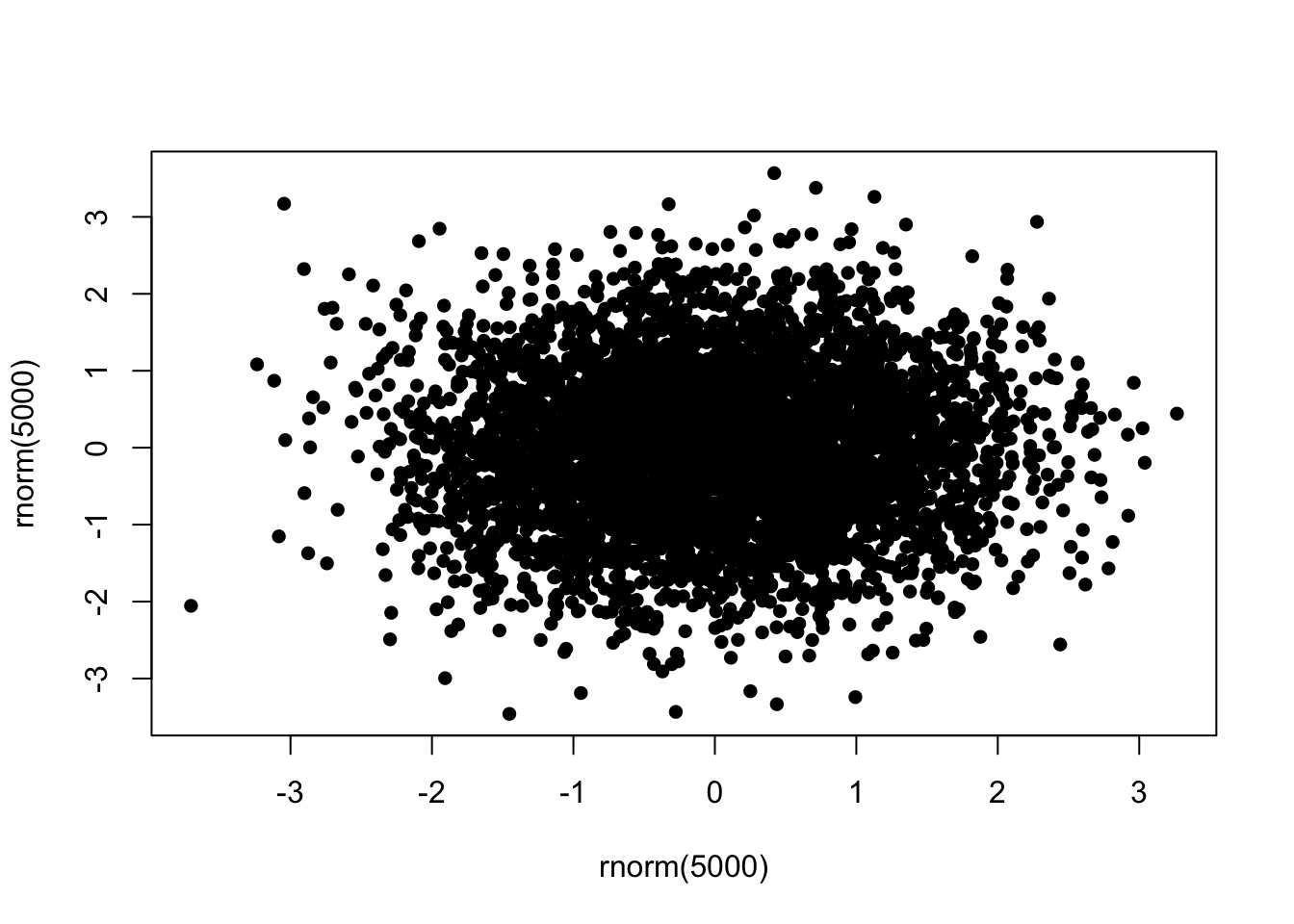
To ‘fix’ this, we can specify a transparent colour in the
col argument by using the alpha function from
the scales package:
library(scales)
plot(x=rnorm(5000),y=rnorm(5000),pch=16,col=alpha('black',0.2))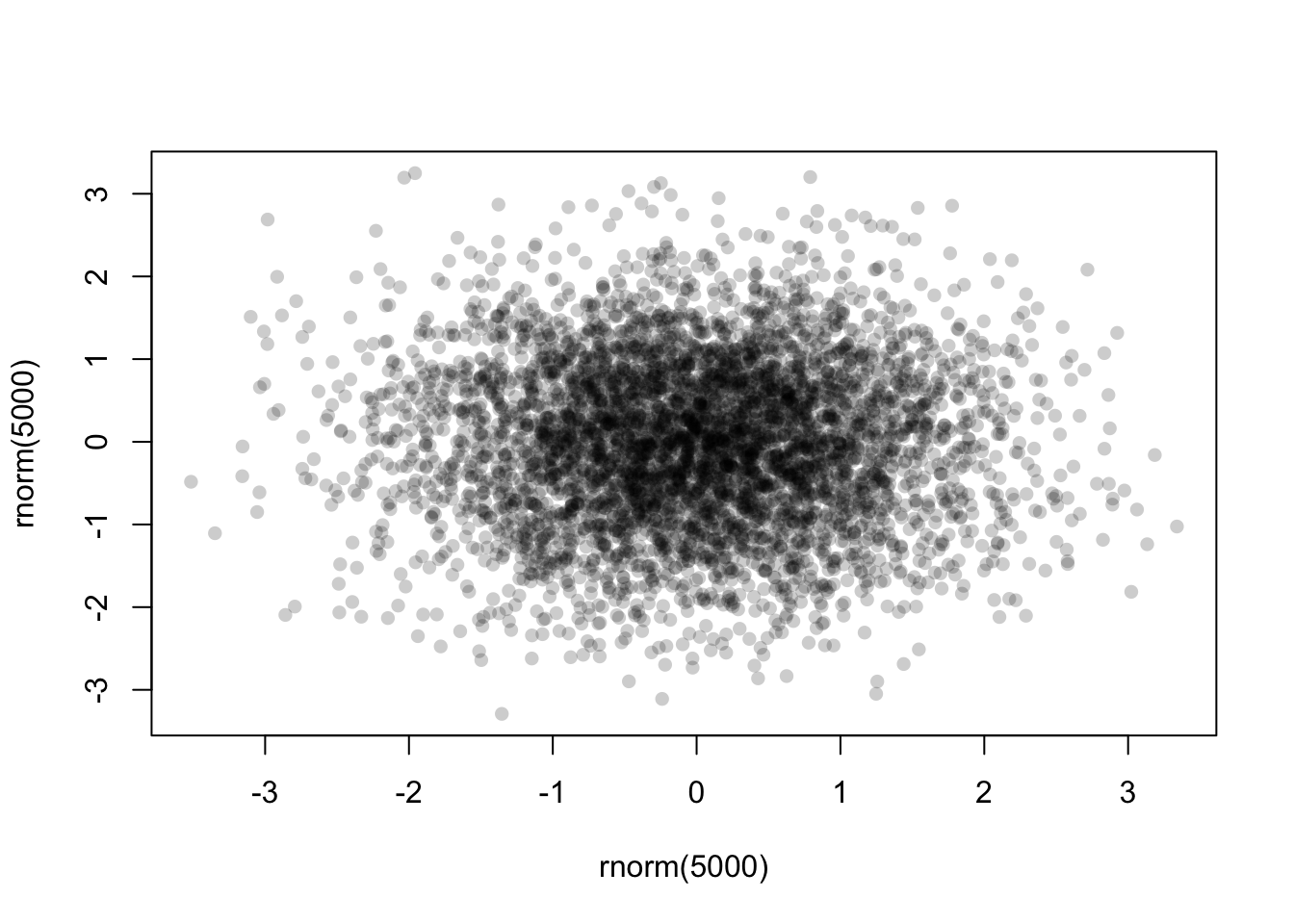
The alpha function takes two arguments - a colour first,
and then the alpha level itself. This should be a number in
\([0,1]\) with smaller values being
more transparent. Finding a good value for alpha is usually
a case of trial-and-error, but in general it will be smaller than you
might first expect!
Now with the transparency we can see a bit more structure in the data, and the darker areas now highlight regions of high data density.
2.4 Data Set 3: Engine pollutants
Download data: engine
This rather simple data set contains three numerical variables, each
representing different amounts of pollutants emitted by 46 light-duty
engines. The pollutants recorded are Carbon monoxide (CO),
Hydrocarbons (HC), and Nitrogen oxide (NOX),
all recorded as grammes emitted per mile.
- Construct three scatterplots to investigate the relationships
between every pair of pollutants:
COversusHCCOversusNOXHCversusNOX
- What are the relationships between the amounts of different pollutants emitted by the various engines? In particular, which pollutants are positively associated and which are negatively associated?
- The strength of a linear relationship can be assessed through the
correlation, which is a number between 0 (no linear relationship) and 1
(perfect linear relationship). Have a guess at the correlation between
these variables, and then check the numerical values with the
corfunction. - Do any of the scatterplots have any outliers?
- If so, can you identify which data points correspond to these outliers. Look at the other data values for these outlying cases - are they extreme on other variables or just one?
- Can you visually indicate the outliers on your scatterplot, e.g with colour?
plot(x=engine$CO, y=engine$HC) ## strong and linear relationship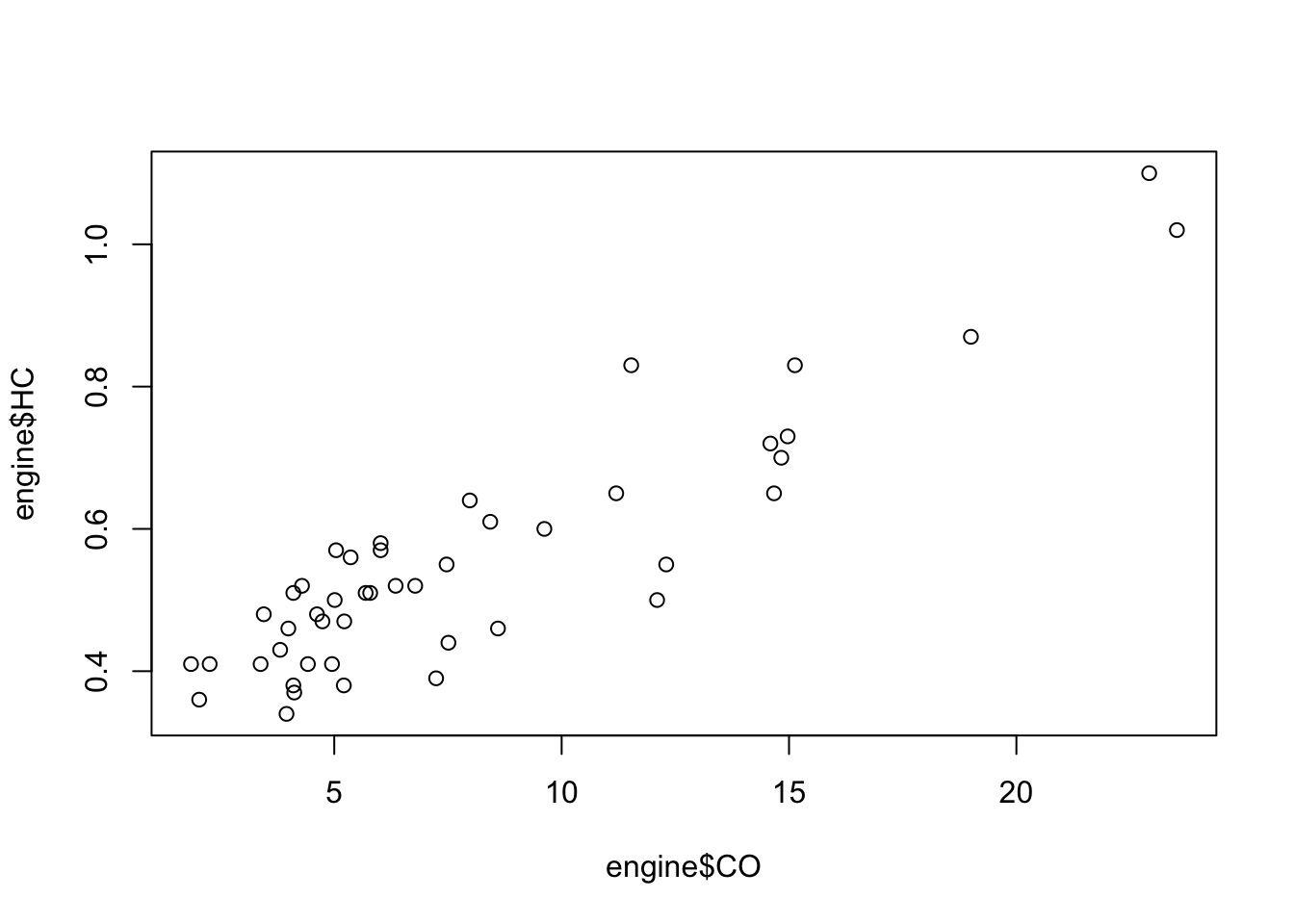
plot(x=engine$CO, y=engine$NOX) ## fairly strong, decreasing non-linear relationship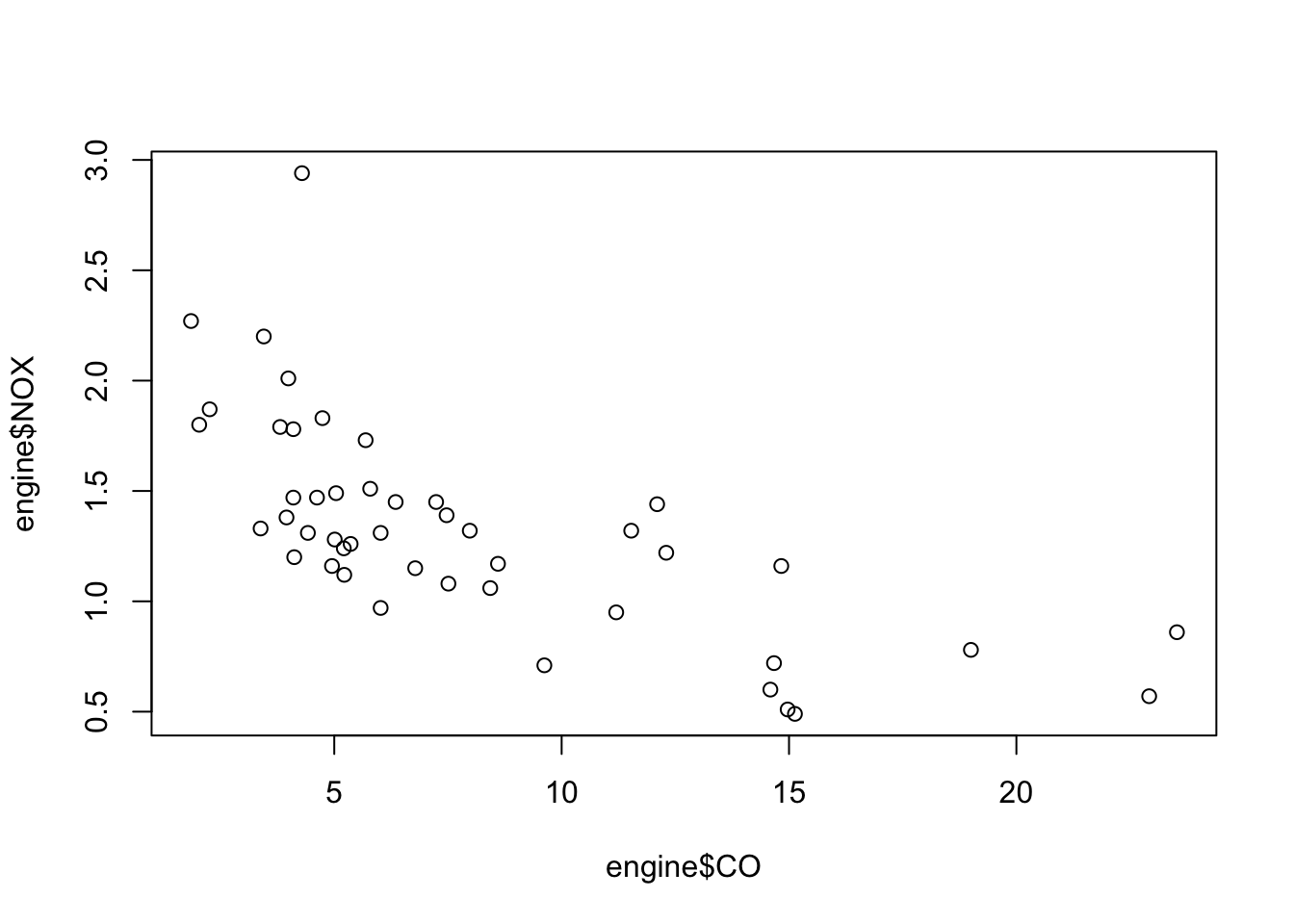
plot(x=engine$HC, y=engine$NOX) ## weaker negative relationship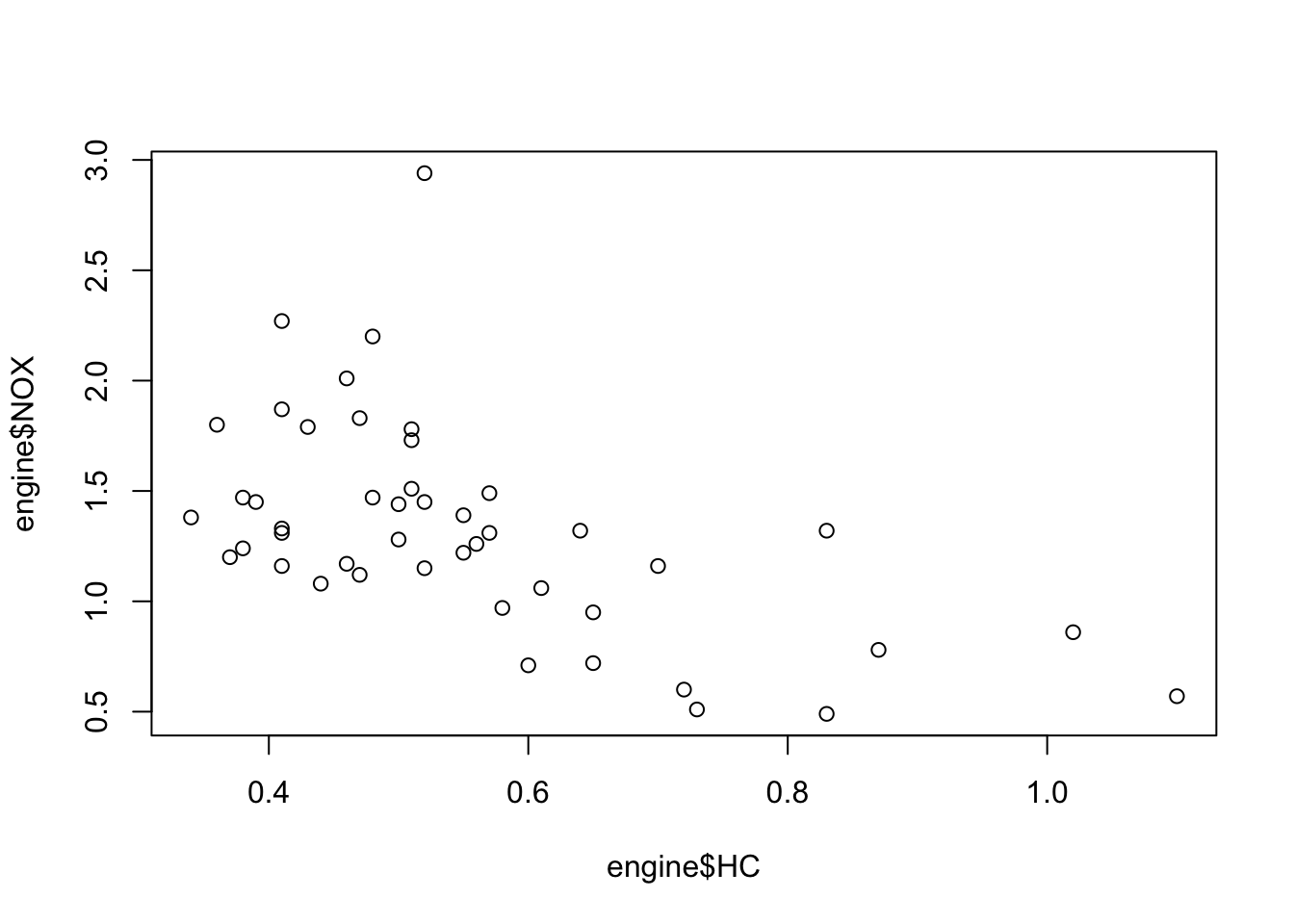
## use cor to find the correlation matrix, i.e. correlation between every pair
cor(engine)## CO HC NOX
## CO 1.0000000 0.9008276 -0.6851157
## HC 0.9008276 1.0000000 -0.5588089
## NOX -0.6851157 -0.5588089 1.0000000## (CO,HC): 0.9
## (CO,NOX): -0.68
## (HC,NOX): -0.55
## agrees with comments on strength of relationship## the scatterplots suggest maybe one large outlier on NOX, and two on CO?
boxplot(engine) ## bocplots suggests a few outliers at the top end of each scale.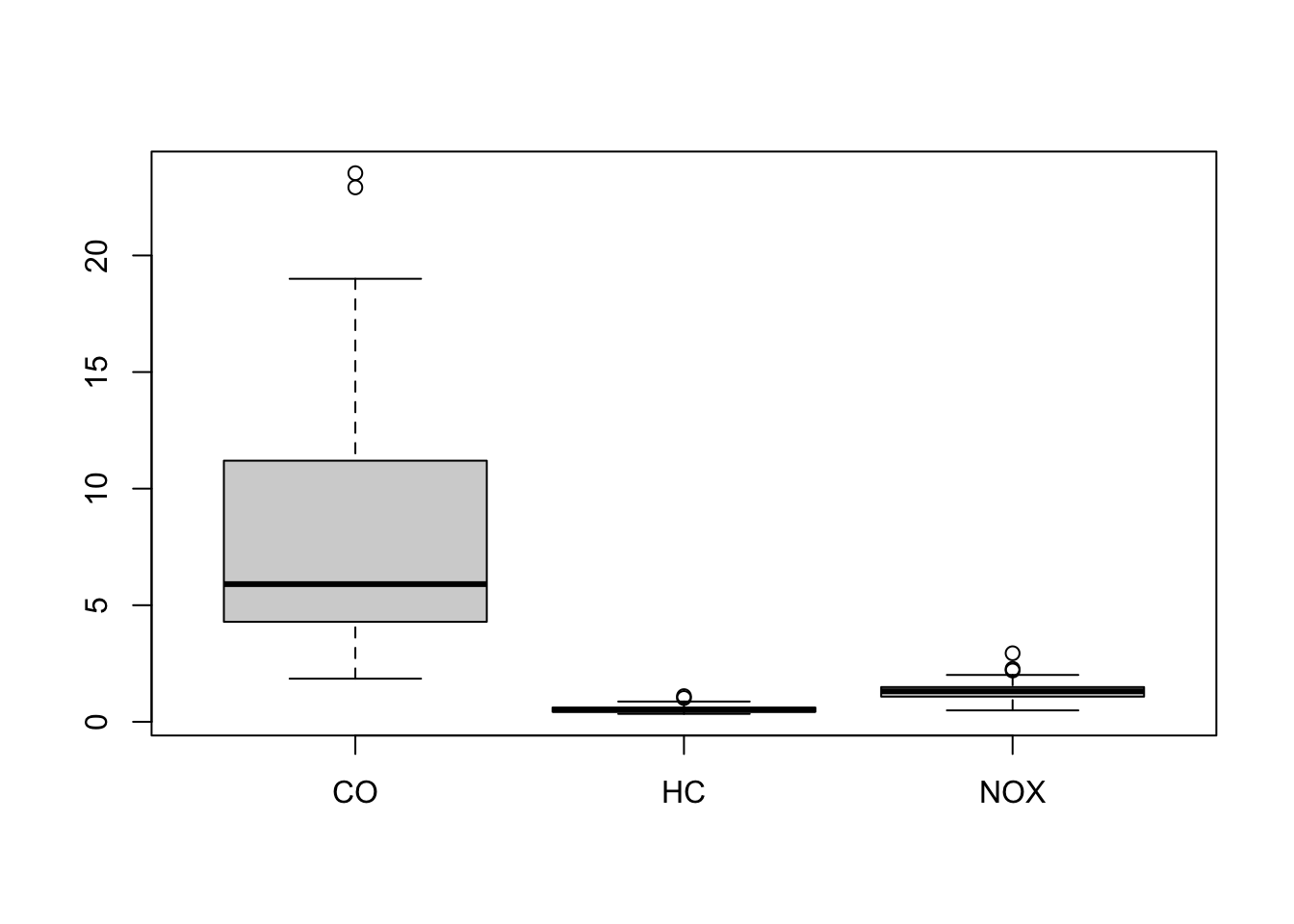
engine[engine$NOX>2.5,] # NOX outlier is case 39## CO HC NOX
## 39 4.29 0.52 2.94engine[engine$CO>20,] # CO outliers are cases 34,35## CO HC NOX
## 34 23.53 1.02 0.86
## 35 22.92 1.10 0.57colours <- alpha(rep('black',length=46),0.5) ## transparent black for all points
colours[39] <- 'red' ## NOX outlier will be solid red
colours[c(34,35)] <- 'blue' ## CO outliers will be solid blue
par(mfrow=c(1,3)) ## redraw plots with new colours
plot(x=engine$CO, y=engine$HC, col=colours, pch=16)
plot(x=engine$CO, y=engine$NOX, col=colours, pch=16)
plot(x=engine$HC, y=engine$NOX, col=colours, pch=16)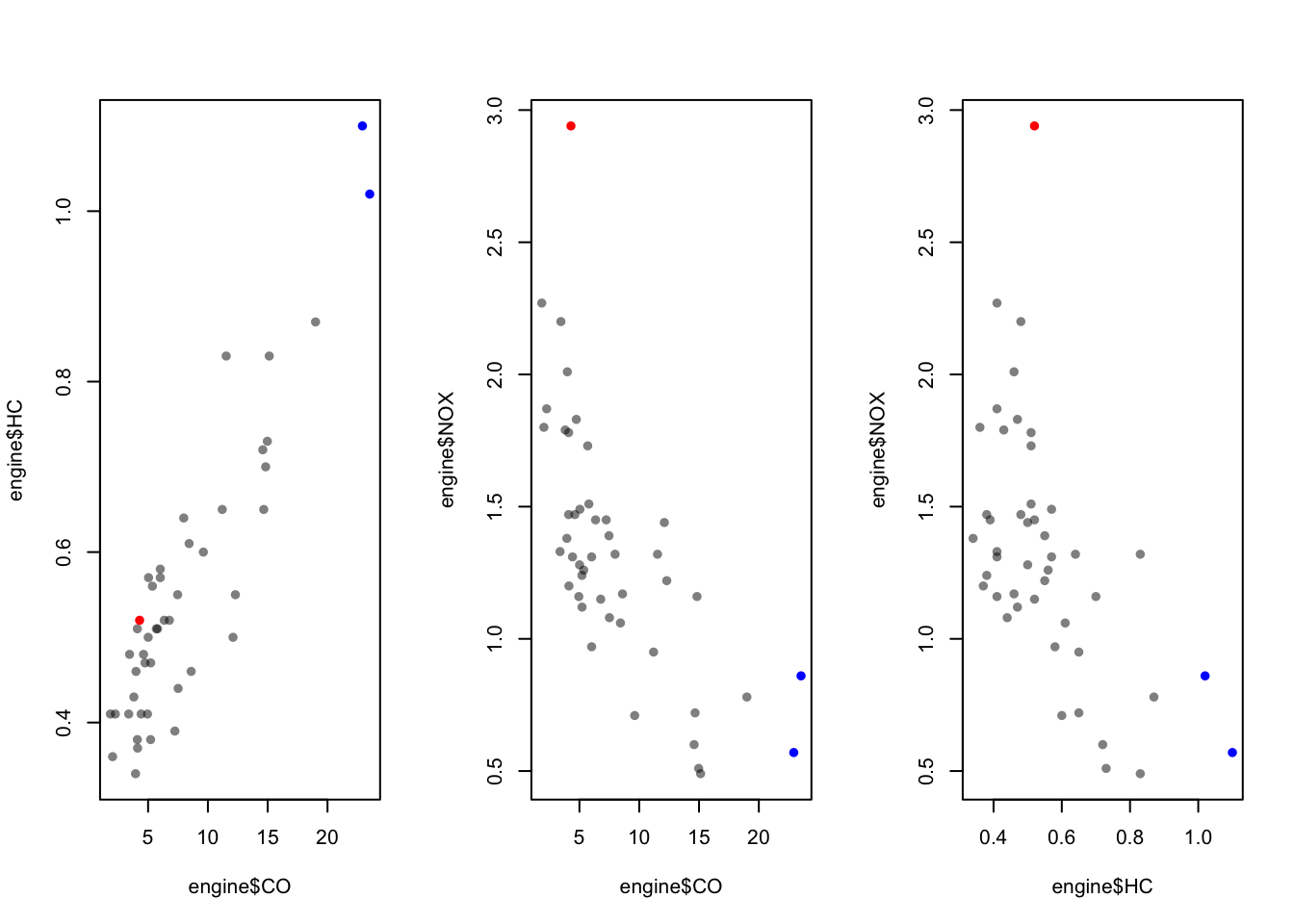
## now we can see that the outliers on CO are also the two largest values on HC2.5 Data Set 4: The evils of drink?
Download data: DrinksWages
Karl Pearson was another prominent early statistician, responsible for number of major contributions: correlation, p-values, chi-square tests, and the simple histogram to name a few.
In 1910, hen weighed in on the debate, fostered by the temperance movement, on the evils done by alcohol not only to drinkers, but to their families. The report “A first study of the influence of parental alcholism on the physique and ability of their offspring” was an ambitious attempt to the new methods of statistics to bear on an important question of social policy, to see if the hypothesis that children were damaged by parental alcoholism would stand up to statistical scrutiny.
Working with his assistant, Ethel M. Elderton, Pearson collected
voluminous data in Edinburgh and Manchester on many aspects of health,
stature, intelligence, etc. of children classified according to the
drinking habits of their parents. His conclusions where almost
invariably negative: the tendency of parents to drink appeared unrelated
to any thing he had measured. The publication of their
report caused substantial controversy at the time, and the data set
DrinksWages is just one of Pearson’s many tables, that he
published in a letter to The Times, August 10, 1910.
The data contain 70 observations on the following 6 variables, giving
the number of non-drinkers (sober) and drinkers
(drinks) in various occupational categories
(trade).
class- wage class: a factor with levels A B Ctrade- a factor with levels:bakerbarmanbillposter…wellsinkerwireworkersober- the number of non-drinkers, a numeric vectordrinks- the number of drinkers, a numeric vectorwage- weekly wage (in shillings), a numeric vectorn- total number, a numeric vector
- Use the
drinksandncolumns to compute the proportion of drinkers for each row of the data set. - Plot the proportion of drinkers against the weekly wage.
- Is there any evidence of a relationship between these variables?
- Do you see anything unusual happening at either end of the scale of the proportion of drinkers?
It is perhaps a little surprising that some trades have 100% drinkers and some 100% non-drinkers. A look at the distribution of numbers in the study by trade (or just a summary table) will help explain why:
- Make a histogram of
n, the counts in each row. What do you find? - Of all the different
trades, how many only have 1 or 2 member in this survey? - Can you find the biggest group with 100% drinkers? What about non-drinkers?
- Create a new dataset which contains only those trades where
nis 5 or more. - Redraw your scatterplot.
- How has the plot changed? Has your interpretation of the relationship between these variables changed?
## have a quick look
head(DrinksWages)## class trade sober drinks wage n
## 1 A papercutter 1 1 24.00000 2
## 2 A cabmen 1 10 18.41667 11
## 3 A goldbeater 2 1 21.50000 3
## 4 A stablemen 1 5 21.16667 6
## 5 A millworker 2 0 19.00000 2
## 6 A porter 9 8 20.50000 17## here we need to make a new variable. We can either make it as a new object
pcDrink <- 100* DrinksWages$drink / DrinksWages$n
## or create a new column in the data set
DrinksWages$pcDrink <- 100*DrinksWages$drink / DrinksWages$n
## and plot
plot(x=DrinksWages$wage, y=DrinksWages$pcDrink,pch=16)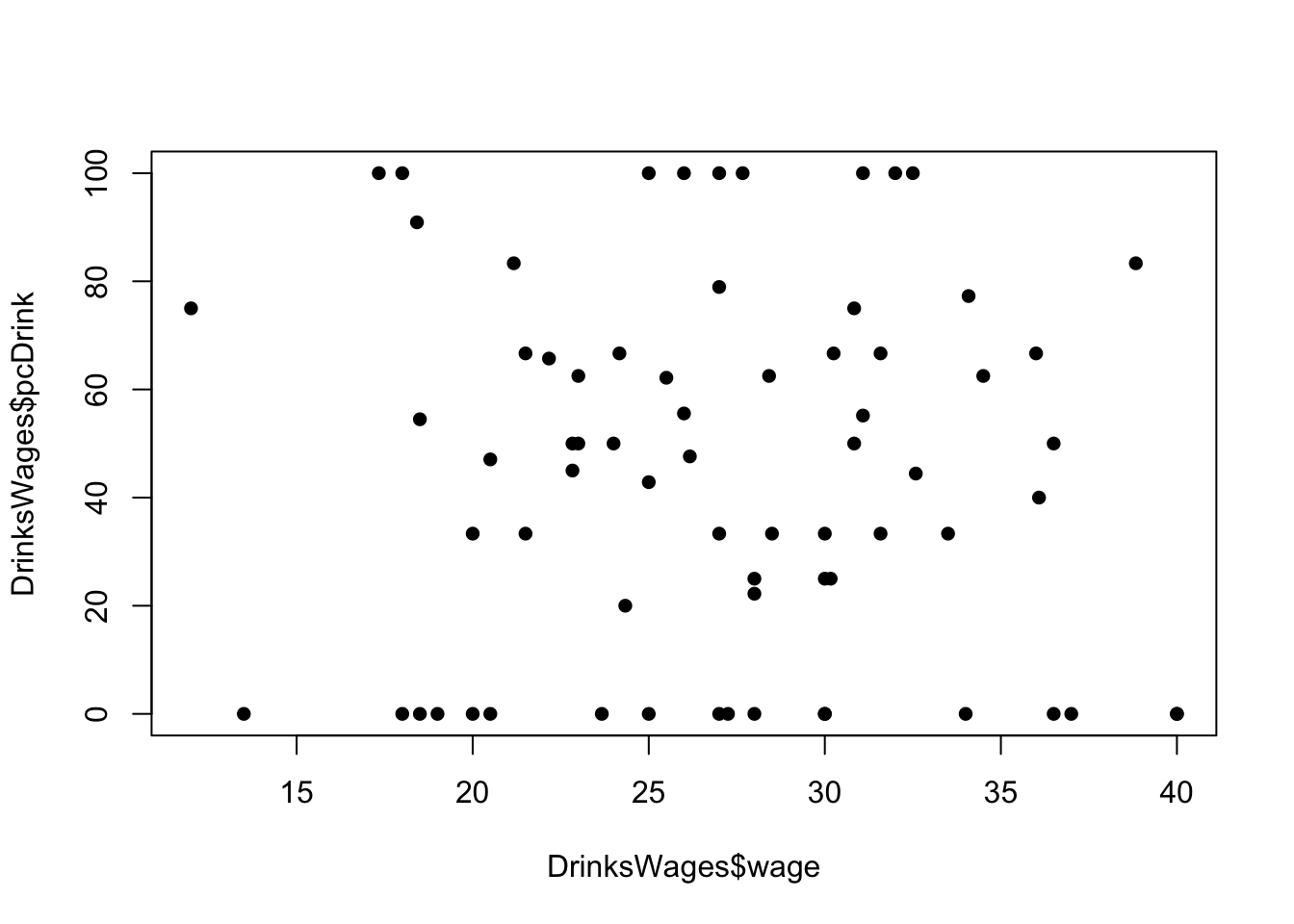
## There doesn't look to be much of a relationship here
## What IS odd are the weird lines at 0% and 100%It is perhaps a little surprising that some trades have 100% drinkers and some 100% non-drinkers. A look at the distribution of numbers in the study by trade (or just a summary table) will help explain why:
- Make a histogram of
n, the counts in each row. What do you find? - Of all the different
trades, how many only have 1 or 2 member in this survey? - Can you find the biggest group with 100% drinkers? What about non-drinkers?
hist(DrinksWages$n,breaks=100)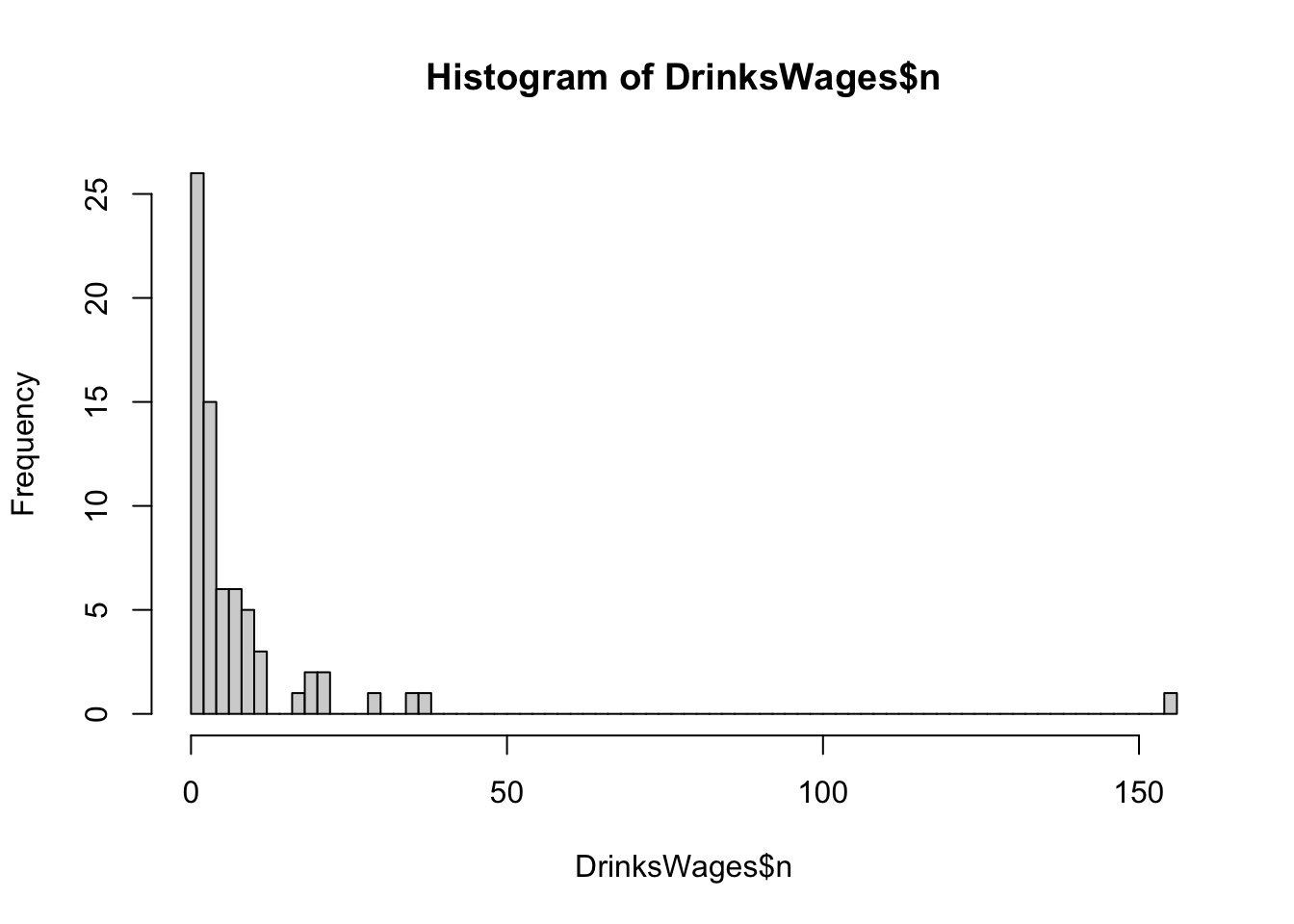
## we have a lot of occupations where we only have a very small number of observations
## and one where we have over 150! This could be distorting the proportions## how many cases are there with less than 2 counts?
nrow(DrinksWages[DrinksWages$n<=2,])## [1] 26## this is close to half of the data set!## look at the data with 100% drinkers
DrinksWages[DrinksWages$pcDrink==100,]## class trade sober drinks wage n pcDrink
## 9 A chimneysweep 0 7 17.33333 7 100
## 21 A platelayer 0 2 18.00000 2 100
## 26 B sadler 0 3 25.00000 3 100
## 36 B linesman 0 2 26.00000 2 100
## 41 B pipelayer 0 1 27.66667 1 100
## 47 B tramdriver 0 1 27.00000 1 100
## 53 C wireworker 0 1 32.50000 1 100
## 68 C picture framer 0 2 31.08333 2 100
## 69 C postman 0 2 32.00000 2 100## chimney sweeps!
## now 100% non-drinkers
DrinksWages[DrinksWages$pcDrink==0,]## class trade sober drinks wage n pcDrink
## 5 A millworker 2 0 19.00000 2 0
## 11 A barman 1 0 23.66667 1 0
## 17 A french polisher 1 0 13.50000 1 0
## 18 A wagon examiner 1 0 20.00000 1 0
## 19 A surfaceman 4 0 18.50000 4 0
## 20 A gardener 2 0 20.50000 2 0
## 24 A billposter 1 0 18.00000 1 0
## 27 B turnroom 1 0 25.00000 1 0
## 33 B wellsinker 1 0 30.00000 1 0
## 37 B timekeeper 1 0 30.00000 1 0
## 38 B jeweller 2 0 28.00000 2 0
## 44 B bottler 1 0 27.25000 1 0
## 46 B gasworker 5 0 27.00000 5 0
## 48 C letterpresser 1 0 34.00000 1 0
## 54 C plasterer 1 0 37.00000 1 0
## 64 C rivetter 1 0 40.00000 1 0
## 67 C chemist 1 0 36.50000 1 0
## 70 C glassmaker 1 0 40.00000 1 0## gasworkers!- Create a new dataset which contains only those trades where
nis 5 or more. - Redraw your scatterplot.
- How has the plot changed? Has your interpretation of the relationship between these variables changed?
## new data set
dw <- DrinksWages[DrinksWages$n>=5,]
## redraw the plot
plot(y=dw$pcDrink, x=dw$wage,pch=16)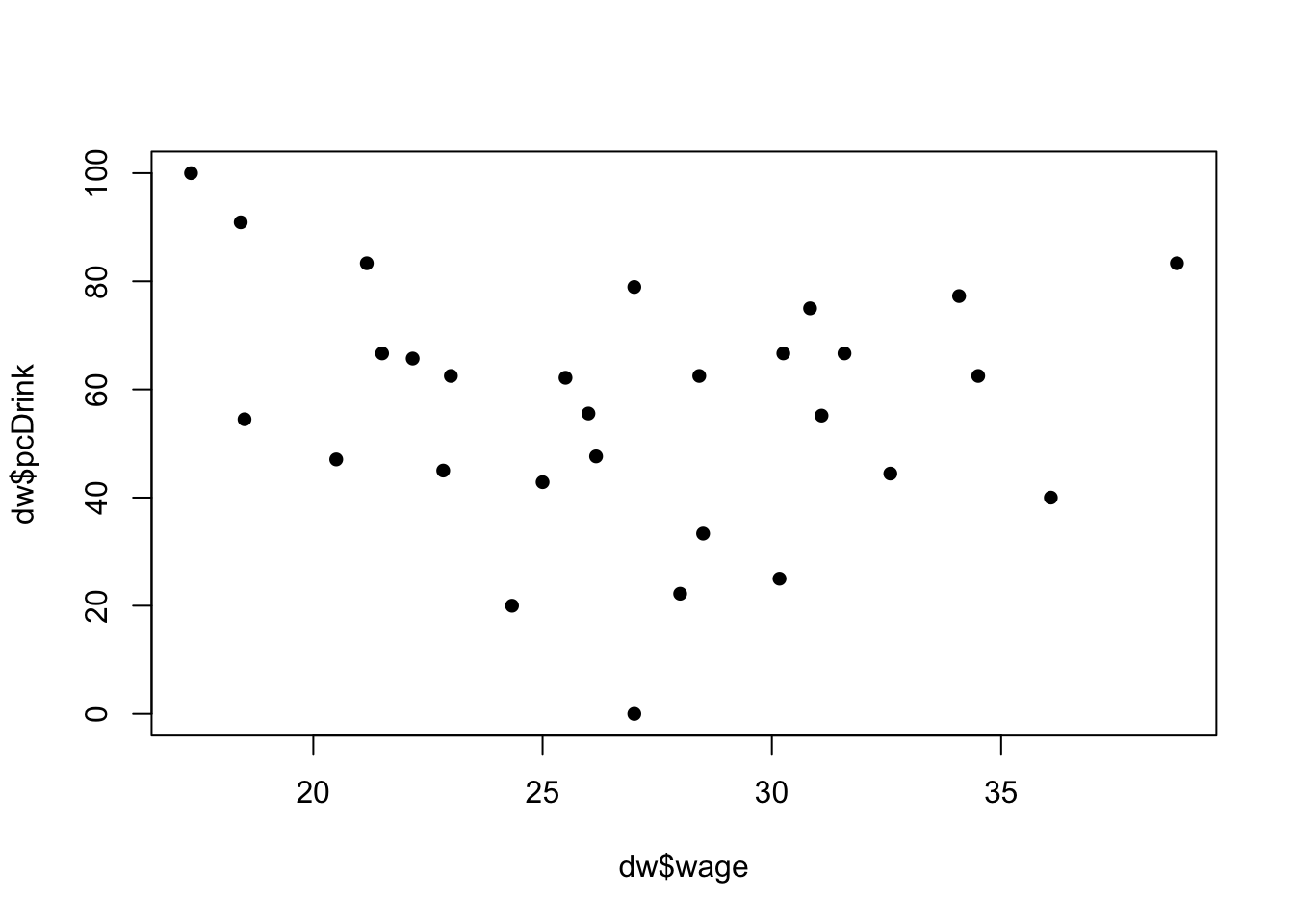
## now we lose the vertical lines, there really isn't much of an observable pattern here
## so how much you earn doesn't impact how much you drink3 Variations on Standard Plots
3.1 A hexbin
When overplotting of data in a scatterplot is an issue, we saw above
that we can use transparency to ‘see through’ our data points and reveal
areas of high density. A hexbin can be though of as a
two-dimensional histogram, where we plot the counts of the data which
fall in small hexagonal regions (squares would work, but hexagons just
look cooler). The shades of the bins then take the place of the heights
of the bars. This technique is computed in the hexbin
package.
# you'll need to install `hexbin` if you don't have it
# install.packages("hexbin")
library(hexbin)
library(grid)
# Create some dense random normal values
x <- rnorm(mean=1.5, 5000)
y <- rnorm(mean=1.6, 5000)
# Bin the data
bin <-hexbin(x, y, xbins=40)
# Make the plot
plot(bin, main="" , colramp = colorRampPalette(c("darkorchid4","darkblue","green","yellow", "red"))) 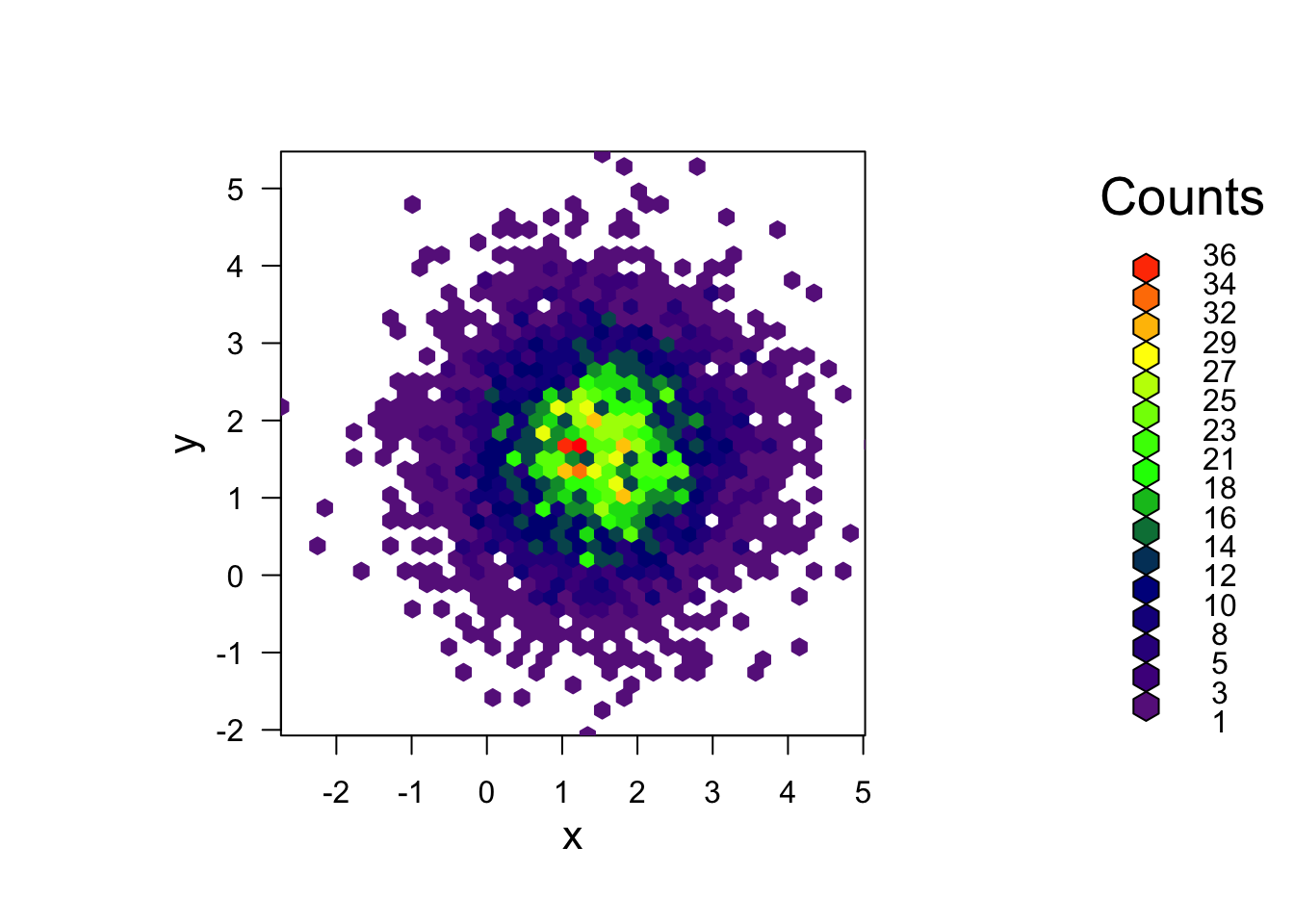
4 More Practice
4.1 Data Set 5: Exam marks in mathematics
Download data: marks
This data set contains the exam marks of 88 students taking an exam on five different topics in mathematics. The data contain the separate marks for each topic on a scale of 0-100:
MECH- mechanicsVECT- vectorsALG- algebraANL- analysisSTAT- statistics
- Explore the data!
- If that’s a little too vague:
- Start with some plots of the individual variables. Look for commonality and obvious differences.
- Think about what you might expect to see here, and investigate those hypotheses.
- Look at the scatterplots between the variables - maybe focus on
STATs for now, as the most familiar subject. - Which subjects have a strong relationship between their exam performance? Which have a weak relationship?
- If we take this as a proxy for the similarity between the subjects, what would you infer?