Maths projects
Cluster Analysis - Jonathan Cumming
Description
Cluster analysis (clustering) is an exploratory statistical technique which is used to identify natural groupings within a large number of observations. Discovering that there are sub-groups in the data is often valuable information, particularly if the different groups of observations have different properties or behaviours - see the Wikipedia page on Simpson's paradox for why this might be important. Simple methods for clustering seek to identify sub-groups of the observations which are "similar" to other observations in the same group, but "different" from data in other groups - these groups then constitute the clusters within the data. Often "similarity" is defined in terms of the Euclidean distance between the data points, and this leads to simple methods such as k-Means. Of course, there are a wide variety of ways you can define "similarity", or even a "cluster", and this leads to an equally broad spectrum of methods which seek to discover these features.
Clustering is widely-applied in the sciences and in industry, making it a useful method in any statistician's toolbox. For example: in biology, analysing genetic information to identify groups of genes related to a particular genetic disease; in marketing, analysing similar purchases during online shopping to make recommendations; in computer science, analysing characteristics of internet connections to distinguish valid activity from hacking attempts; in internet search engines, identifying clusters of similar webpages due to the frequency they use particular keywords; in medicine, finding clusters of patients with similar outcomes after treatment.
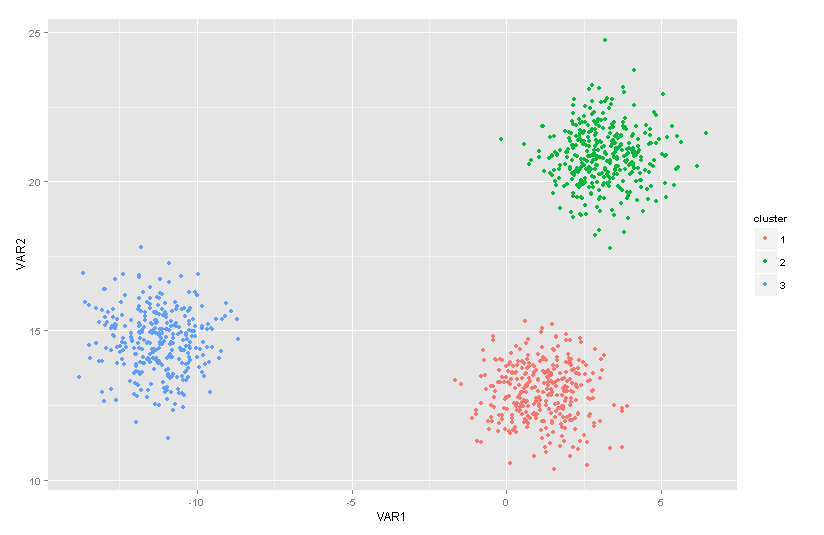
In this project, you will learn about the key concepts behind cluster analysis. You will study and implement some standard clustering methods, and evaluate their strengths and weaknesses through application to data. There are then several questions which you could pursue depending your interest. Some examples would be:
- How do we predict to which cluster (if any) a new observation will belong? (the classification problem)
- How do these methods perform as we increase the number of variables? (the curse of dimensionality)
- How can we use ideas of probability and distributions in clustering? (probabilistic or model-based clustering)
- How would things change if we only see the data points sequentially and one at a time, rather than all at once? (so called "online" clustering)
- How do we assess how many clusters are in the data?
This project has a focus on data analysis and statistical computation. Familiarity with the statistical package R, general statistical concepts, and data analysis are essential.
Prerequisites/Corequisites
Statistical Concepts II, Statistical Methods III
Web Resources
- There is a large amount of material available on the web; start with the wikipedia page for example.
- Animation of k-Means clustering in action: link.
- The R statistical package can be downloaded from here. The R packages cluster and mclust are of particular relevance.
{kind=link}
Books
Many books contain suitable introductory material:
- The library has many books on this topic (link). A good starting point would be the book by Everitt
- The early chapters in any book on clustering or cluster analysis will cover the background in sufficient detail. Books targeted at a particular application area will likely have less mathematical detail. Many books on multivariate data analysis will also likely touch on this topic.