Project III: Statistical Learning and Classification
Jonathan Cumming
Jonathan Cumming
Digital information has become so entrenched in all aspects of our lives and society, that the recent growth in information production appears unstoppable. Each day on Earth we generate 500 million tweets, 294 billion emails, 4 million gigabytes of Facebook data, 65 billion WhatsApp messages and 720,000 hours of new content added daily on YouTube. In 2020, the total amount of data created, captured, copied and consumed in the world was estimated at 59 zettabytes (one zettabyte is 1021 bytes, or a trillion gigabytes).
Clearly, no human being could ever analyse or understand such vast quantities of information! Instead, during the past 20 years has seen the rapid development of new tools in the field of statistics, giving rise to new fields such as data science, machine learning, and artificial intelligence. Most of the methods used in these areas are soundly based in statistics and mathematics, however they've arguably achieved better PR than the more traditional disciplines!
In this project, we will focus on the problem of classification, where the objective is to predict to which group a particular data point belongs. While, superficially, an abstract problem, the range of applications are enormous: does this patient have the scary disease or not? Does this pattern of network activity indicate a cyberattack? What are the interests of this person given their search history (and what advertising should I show them)? Are the text reviews for these movies positive, negative, or neutral?
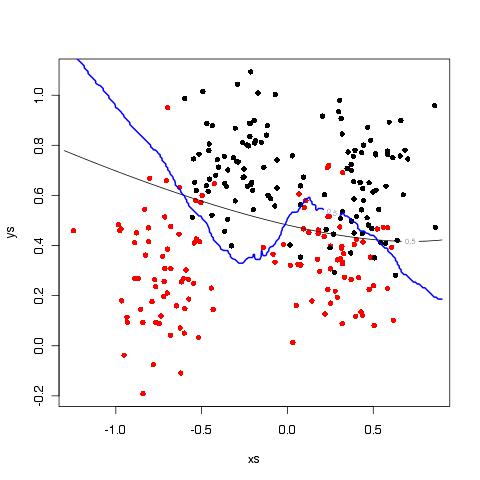
Two models for classifying points as black or red. The blue exhibits a low bias but high variance, and the grey is the opposite with low variance but high bias. Which is best?
The answers to all of these questions require the application of statistical methods to learn from data - hence statistical learning - to try and make accurate predictions of some outcome of interest. These methods are key tools in the toolbox of a data scientist, and often sit at the intersection of statistics and computer science. The initial goals of the project will be to explore some key statistical learning methods, such as
- Simple classification methods - elementary methods make minimal assumptions and are easily applied but can lack the sophistication to tackle complex problems, such as k-nearest neighbour, and Naive Bayes
- Linear classification methods - attempt to divide groups by determining some form of linear boundary between them, such as logistic regression, linear discriminant analysis, and support vector machines.
- Tree-based methods and models, such as CART (classification and regression trees), random forests, and related topics such as boosting and bagging
With this understanding you may then take the project in whatever direction you find most interesting, which might include going deeper into the methodology of a family of techniques which interests you, or finding a data set to use for a real-world application.
This project has a focus on statistical methodology and data analysis. Familiarity with the statistical package R (or equivalent languages such as Python), general statistical concepts, and data analysis are essential.
Prerequisites
- Statistical Inference II - for familiarity with standard statistical ideas and experience with R.
- (optional) Statistical Modelling II - helpful for understanding simple statistical models, but not essential
Further reading
Many books contain suitable introductory material. All books below are available freely and in full online.
- The linked wikipedia pages above are a good place to start
- An Introduction to Statistical Learning by James, Witten, Hastie and Tibshirani provides a more gentle introduction to the subject and contains many examples in R.
- The Elements of Statistical Learning by Hastie, Tibshirani and Friedman covers similar topics, but goes more into detail.
- Probabilistic Machine Learning: An Introduction by Kevin Murphy. A very comprehensive overview and probably the most up-to-date introduction to machine learning.