Description
Finding clusters in data sets is an old statistical problem. One is given a multivariate data cloud, and one is interested in identifying certain subgroups, regions, or clusters so that the data "within are more similar than between". Sometimes this cluster structure is directly visible from the data, as in the example figure below, but often (especially for dimensions >3) this will not be the case. In either case, one needs appropriate statistical techniques to identify these clusters. A cluster is typically defined by (i) a cluster center and (ii) and allocation of neighboring data points to this cluster center. The number of clusters may be known or unknown, and inferring the numbers of clusters from the data poses additional challenges. Clustering is an unsupervised statistical learning technique, which is not to be confused with classification, where the clusters are already known, and the question is only how to allocate new data points to clusters.
In this project you will investigate several (traditional as well as modern) clustering techniques, such as k-means, mean shift clustering, or Gaussian mixtures.
You will study some theoretical background of these methods, and apply them on different data sets, which may be taken from a wide range of applications
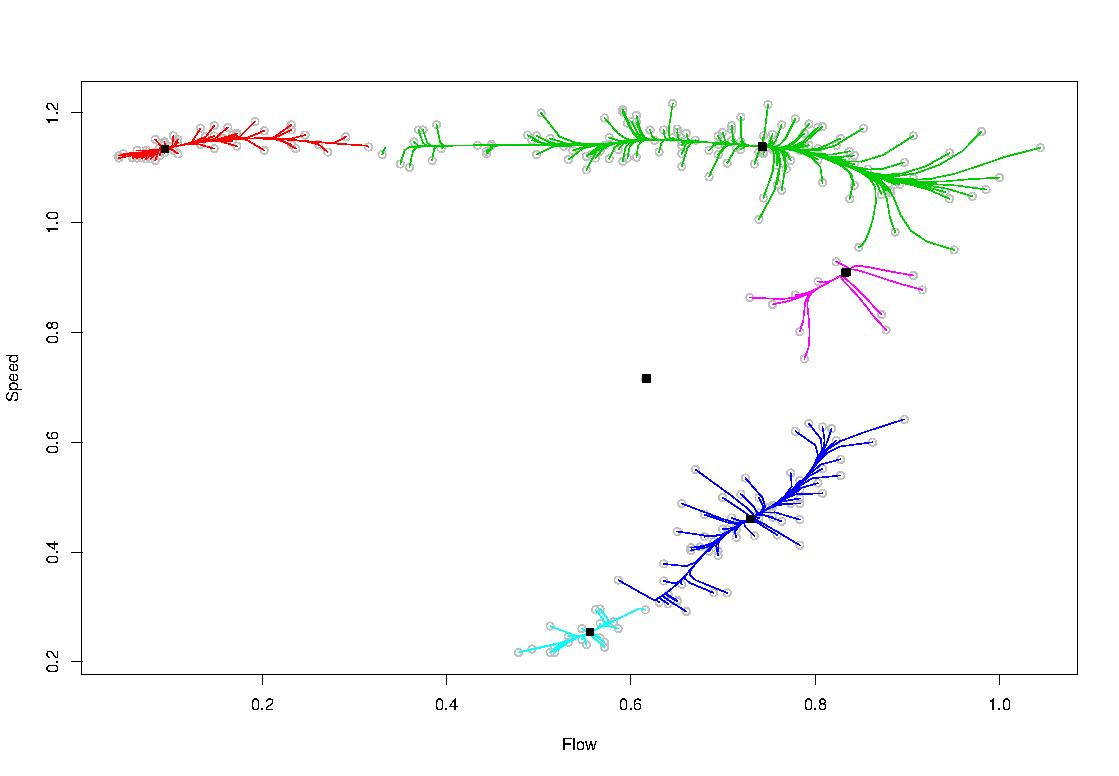
within the social or natural sciences, as well as engineering. An example for the result of a cluster analysis is provided below, where a "speed-flow diagram" (consisting of speed
and flow measurements in 5-minute intervals on an US highway) led to six identified clusters.
Prerequisites
- Knowledge on R is useful, but not necessary.
Resources and Examples
- Hastie, T., Tibshirani, R. & Friedman, J. (2001): The Elements of Statistical Learning, Springer, 2001
- The Wikipedia page: Cluster analysis
- Mean shift clustering in high dimensions - a texture classification example.