Maths projects
Statistical Classification - Rachel Oughton & Jonathan Cumming
Description
Classification methods are used when a data observation needs to be categorised as belonging to one of a predefined set of classes, based on its characteristics. A training dataset, where the class of each observation is already known, is used to 'train’ the model, and then as new data arrive they can be classified using the model. For example, each of a collection of news articles is determined to be either ‘real’ or ‘fake’. Various properties are extracted from each article, such as length, types of word used, source, etc., and these are used to train a classification model. When a new article emerges, the same properties are extracted, and the model can determine with some level of confidence whether the article is real or fake.Classification is a useful statistical skill to have, with example applications including medical (does a patient have a particular disease?), email (is an email spam or not?), e-commerce (based on their browsing, is a prospective customer likely to make a purchase?) environmental (classifying land cover from aerial photographs) and many others.
Approaches to classification vary. The nearest neighbour classifier simply assigns the new data point with the same class as its nearest neighbour in the training data. In Linear discriminant analysis, we try to find a function of the variables that partitions the space into the different classes. Logistic regression treats the problem as a regression in which the response variable is categorical. One can also build classification trees, where the characteristics are used sequentially to categorise a data point. Each of these approaches has different strengths and weaknesses in terms of accuracy, user interpretability, level of statistical rigour and so on.
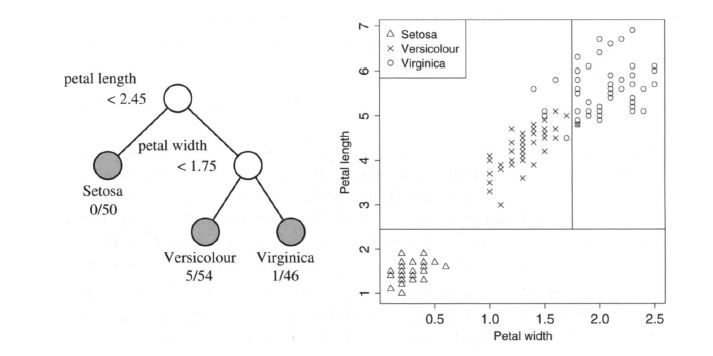
Classification tree model for a dataset on Irises. At each node, an observation
goes to the left child node if and only if the condition is true.
The pair of numbers
below each terminal node gives the number misclassified and the node sample size.
In this project, you will study a variety of classification methods and apply them to real data. Two datasets we suggest are:
- Mushrooms – classifying mushrooms as edible or poisonous based on their physical characteristics
- Twitter gender – classifying twitter account holders as male, female or brand (non-human) based on their profile, behaviour and one randomly selected tweet
It is not hard to find other datasets suitable for classification, for example at the Office for National Statistics or Kaggle.
There are a number of directions you could take with your project, such as
- Investigating modelling problems such as model parsimony compared to accuracy
- Looking into Bayesian methods for classification
- Investigating measures of confidence in classification
- Considering clustering, an unsupervised learning problem in which the groups/classes are unknown
- Comparing several different classification methods for their accuracy and efficiency
- Working on developing the best possible classifier for a particular dataset
In this project there will be a lot of data analysis and statistical computation. It is therefore essential to be familiar with the statistical package R, as well as general statistical and data analysis concepts.
Prerequisites/Corequisites
Statistical Concepts II, Statistical Methods III
Web Resources
- There is a large amount of material available on the web; start with the wikipedia page for example, and the topics linked above.
- The R statistical package can be downloaded from here. See the glm function for logistic regression, the lda function for linear discriminants, and the class package for nearest-neighbour and other methods.
- R-bloggers has many useful R articles, for example classifying text messages and importing data into R.
Books
Many books contain suitable introductory material:
- Chapter 4 of The Elements of Statistical Learning (available for download from Springer) provides a good overview.
- The handbook of statistical analysis and data mining applications is approachable and gives a good overview from a data science perspective.
- Model-based clustering and classification for data science : with applications in R
- Books on related topics may also contain useful background (supervised learning, cluster analysis, data mining, discriminant analysis).